How should you pin dependencies and why?
What Is Pinning and Why Is It so Important?
With the term pinning we are referring to the practice of making explicit the version of the
libraries your application is depending on. Package managers like npm or yarn use
semver ranges by default, which basically allows you to install a “range” of
versions instead of a specific one.
By freezing the dependencies we want to achieve repeatable deployment and make sure that every developer is testing on the very same codebase.
Why Did Package Managers Default to Semver?
The main reason is to automatically get updates every time we run npm install (assuming you’re not
using a lock file, more on that later). This is done because we want to get security fixes as fast
as possible. The theory behind that is that
semantic versioning should protect us against
breaking chances, while still getting the security fixes.
What Happens When Semver Fails?
Unfortunately semantic versioning is far from being infallible and breakage might occur. Since multiple dependencies can be updated at once when that happens you will have to manually check which one to blame, and then you will be forced to pin it to fix the issue.
With pinning, you will have to make a PR to update your dependencies and thus get some feedback from the automated tests. So you will know exactly which dependency is going to break your app before that happens.
Tests Can Fail Either
Truth is that tests are not perfect either and chances are you probably didn’t read the release notes looking for breaking changes before merging a green-light PR. Nevertheless pinning still has a big advantage even when the failure is not caught in time: instead of randomly looking for which dependency broke your code, you will be able to bisect the issue very quickly. Git bisecting is a quick way to roll back to previous commits and find out which one introduced the regression. Instead of doing it manually a git bisect allows you to specify a good commit and a bad commit, then it will pick up a commit in the middle and ask you if it’s good or bad. Depending on your answer it will divide the leftmost or rightmost interval and iterate the process until the guilty commit is detected. The whole process can be automated and it’s usually very quick.
Downsides of Pinning
Automation
You may be asking who is going to PR the repo every time a new dependency gets released, because this is a very tedious task to be done manually. Fortunately there are several tools you can use to automate the process, like Renovate. Such tools will constantly check for dependency updates and take care of automatically PR your repo.
Libraries
The biggest downside of pinning concerns libraries development. If you are publishing you own
library to npm, and you decide to pin the dependencies then the incredibly narrow range of versions
will almost certainly lead to duplicates in node_module. If another package pinned a different
version you will end up with both and your bundle size will increase (and thus the loading times).
According to Rhys Arkins (the author of Renovate), even if both
authors are using a service like Renovate this is still not a good idea:
Even if both projects use a service like Renovate to keep their pinned dependencies up to date with
the very latest versions, it’s still not a good idea — there will always be times when one package
has updated/released before the other one, and they will be out of sync. e.g. there might be a space
of 30 minutes where your package specifies foobar 1.1.0 and the other one specifies 1.1.1 and
your joint downstream users end up with a duplicate.
It must be noted that despite our best efforts’ duplication is a “characteristic” of yarn and a
simple yarn upgrade against an existing lock file does not mean that the whole tree gets shaken
for duplicates. You will need post-processing of lock files using
yarn-deduplicate to superseed this issue.
Obviously everything we said about duplication doesn’t apply to Node.js libraries, because the bundle size doesn’t matter on the server.
We explained why package.json pinning is a bad idea, but you may still be wondering if it is wise
to publish the yarn.lock file along with your library.
When you publish a package that contains a yarn.lock, any user of that library will not be
affected by it. When you install dependencies in your application or library, only your own
yarn.lock file is respected. Lockfiles within your dependencies will be ignored.
Since the library lock file will be ignored when it gets installed as a dependency, it won’t produce any duplication.
Upgrade Noise
Going through dozens of PRs each and every day can be annoying. Fortunately Renovate gives you several solutions to deal with the problem, like auto-merging (this may sound scary, but if you don’t have full coverage you could automatically merge patch updates while manually merging minor and major updates), branch auto-merging (it’s basically the same, but the dependency are merged in a test branch which can be periodically merged back into master), scheduling (which allows you to avoid immediate notifications) and packages grouping (Apollo-Client and all it’s related packages in one PR).
How to Pin Packages
package.json And the Sub-Dependencies Problem
Historically the most common way to pin dependencies was to specify an exact version in your
package.json, for example using the --save-exact parameter with npm install (you can make it
default by adding save-exact=true to your .npmrc). With yarn you can use --exact / -E.
Unfortunately pinning in package.json will protect you against breakage of a very small portion of
your packages. If fact even when you pin a package all of its dependencies will still be free to
update: you will protect yourself against a single bad release, but you will still be exposed to
dozens through subdeps.
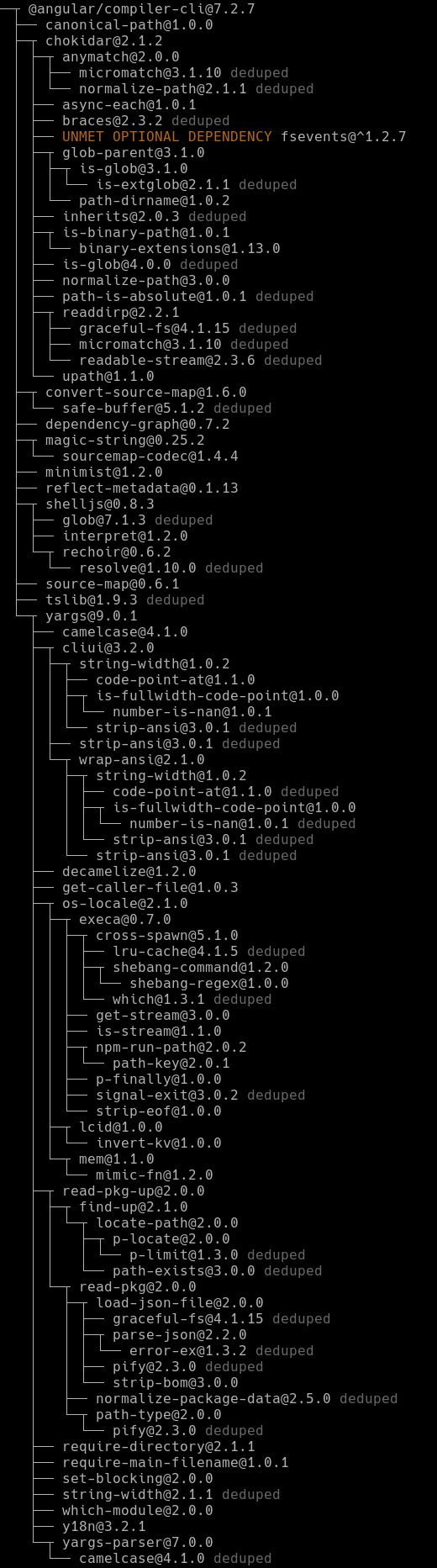
Even if we pin @angular/compiler-cli we would still be exposed to dozens of sub-dependencies
To make things worse, chances that a sub-dependency will break your app increase with package.json
pinning compared to semver: you’re going to use unpinned (and thus newer) subdeps with older pinned
packages and that combo will probably be less tested.
Lock Files to the Rescue
Both yarn and recent npm versions allow you to create a lock file. This allows you to lock each and every package you depend on, including sub-dependencies.
Despite what some people think, if you have "@graphql-modules/core": "~0.2.15" in your
package.json and you run yarn install, it won’t install version 0.2.18: instead it will keep
using the version specified in yarn.lock. That means that your packages will practically be
“pinned” despite not actually pinning any of them in package.json.
To upgrade it to 0.2.18 you will have run yarn upgrade @graphql-modulules/core (note that it
won’t upgrade up to 0.4.2, because it will still obey package.json).
If a package is already at the latest version you can still use yarn upgrade <package> to update
its sub-dependencies.
Unfortunately it won’t also update package.json to reflect ~0.2.18 because technically there is no
need (we’re already in range). But honestly a lock file provides way less visibility compared to
package.json, because it’s not designed to be human-readable. So if you’re looking for dependency
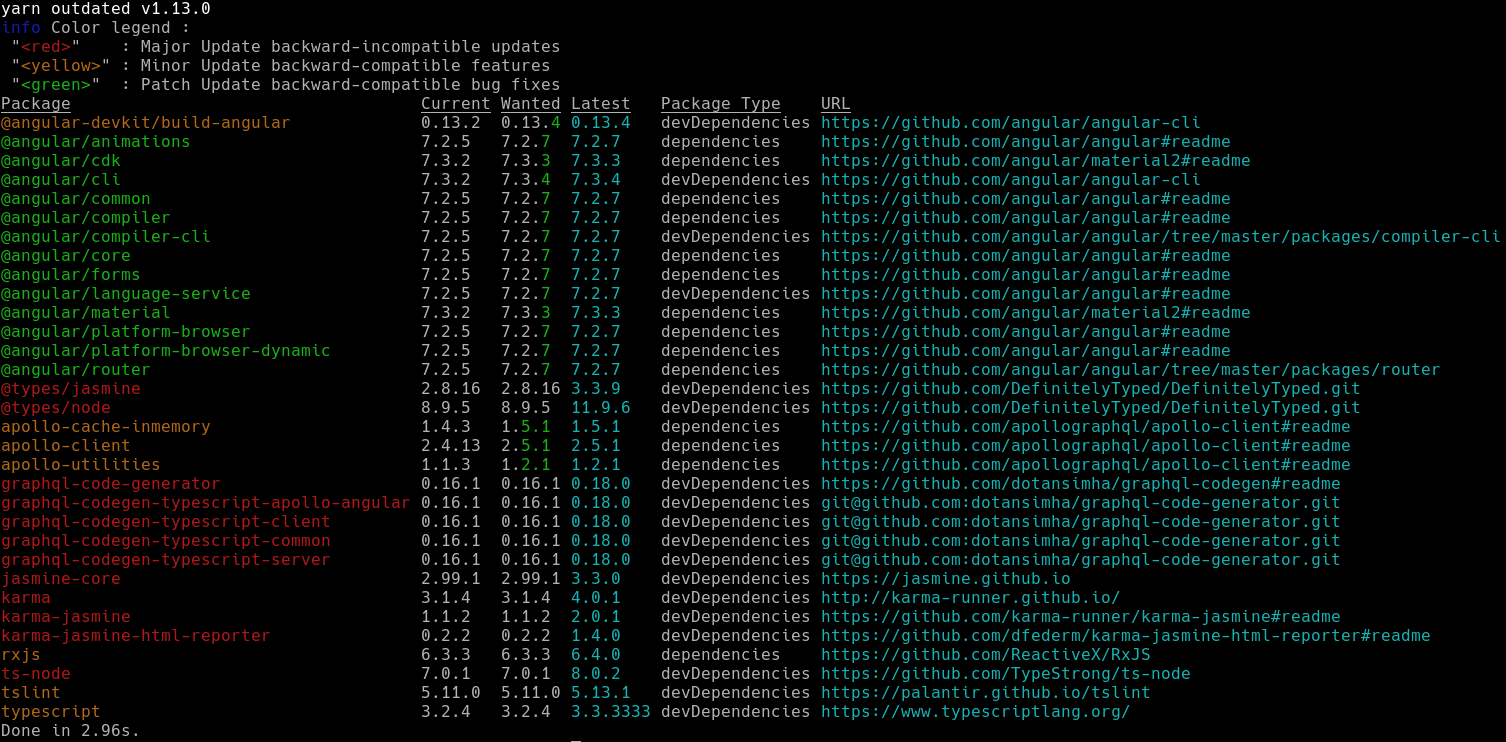
updates you will have a hard time figuring it out, unless you’re using yarn outdated. It eases
your work by looking through the lock file for you and reporting all the available updates in an
easy-to-read format.
Even with a lock file an unexperienced user could simply run yarn upgrade and update all
dependencies at once. As we discussed previously this is very bad to keep track of dependency
updates, and you could have hard times figuring out which package to blame for breakage.
Why Not Both?
In theory, you could get the best of both worlds if you use --exact while still using a lock file:
a human-readable format, protection against all sources of breakage (including sub-deps), protection
against unwanted mass-upgrades ( yarn upgrade won’t update anything if package.json is pinned).
You get the best of both worlds, but this solution has some downsides as well. If you ever used
tools like Angular CLI and in particular commands like ng new or ng update you probably noticed
that some dependencies like zone.js, rxjs or typescript will get tighter ranges (like ~ which
means patch versions only) compared to others. This is because the Angular team knows that some
packages could easily break a certain version of the framework and thus suggest you to not upgrade
over a certain version: if you want a newer version they advise you to upgrade Angular itself
before. By pinning package.json you will loose such useful advices and, if your test coverage is not
optimal, risk to catch some subtle issues.
Conclusion
The ideal solution would be to use Renovate with
updateLockFiles enabled and
rangeStrategy set to bump.
That way package.json will always reflect yarn.lock to provide a human-readable format. At the
same time package.json won’t be pinned, so theoretically you could be able to use it to instruct
Renovate about which dependencies to
automerge. I said theoretically
because I would love Renovate to automerge in-range dependencies if automated tests are passing,
while still undergoing through manual confirmation if they are out of the range specified in
package.json. Unfortunately it is only possible to automerge either major, minor or patch
versions, but not according to package.json ranges. If an in-range option was available you could
use package.json to specify how confident do you feel about auto-merging a specific package: if you
feel comfortable you could use ^, if you feel more cautious just a ~, while if you want to
manually approve every and each upgrade simply pin it with --exact.
For example let’s say I have the following entries in my package.json:
{
"tslib": "^1.9.0",
"zone.js": "~0.8.26"
}Currently, if you set automerge to “patch” when zone.js 0.8.27 gets released it will
automatically merge the PR and the same would happen for tslib 1.9.1. Unfortunately once tslib
1.10.0 gets released it won’t be automatically merged, unless you decide to set automerge to
“minor” (but then zone.js 0.9.0 will be automatically merged, which is not what we want).
Basically I’d like renovate’s automerging policy to obey package.json: ^ means automerge “minor”
on current package ~ means automerge “patch” on current package pinned version means never
automerge the current package.
It’s a way to get a more fine-grained control on the automerging policy, because some packages can be more risky than others.
Since we are stuck with either major, minor or patch for automerge, the only compelling reason
to avoid package.json pinning is if you’re using tools like ng update and you don’t want to loose
upstream update policies. If that doesn’t bother you, you should add package.json pinning on top of
your lock file.
An Important Note about Libraries
Everything we said in the conclusion applies to normal applications, but not libraries. As we said
previously with libraries we want to use wider ranges to prevent duplication. Unfortunately the
bump rangeStrategy basically
forces you to always use latest and greatest version, which could create some duplicates.
Fortunately we also have the update-lockfile
rangeStrategy which bumps the
version in the lock file but keeps the range unchanged unless the update is out of range (if you
range is ^1.9.0 and 2.0.0 gets released it will bump the range).
Join our newsletter
Want to hear from us when there's something new?
Sign up and stay up to date!
*By subscribing, you agree with Beehiiv’s Terms of Service and Privacy Policy.