How trivago Brought Order to APIs with GraphQL Mesh
Most GraphQL Gateway and general GraphQL discussions focus on customer-facing applications—aggregating microservices behind a single endpoint for web and mobile clients, enabling frontend teams to query exactly the data they need without multiple round trips. Trivagos use case and perspective were different.
Background
We had a problem that many growing companies share: too many internal APIs, too many ways to access data. Our admin tools were scattered across multiple systems with wide-ranging tech stacks and overlapping features. One dashboard pulled from a REST endpoint. Another hit a database directly. A third relied on an analytical view that someone had created years ago and nobody fully understood anymore. Each had its own authentication quirks, its own data model, its own gaps in documentation. Building even a small CRUD tool for internal use meant integrating with multiple services and mentally stitching the results together.
In 2020, we looked at this situation and started a journey to unify our internal APIs for administration purposes. We decided to go with GraphQL—even though the community didn’t have many documented use cases for this kind of internal application. The goal was not to build a public API gateway. We wanted an internal lens: a single GraphQL layer that could sit in front of our fragmented services and present a unified, queryable interface to our own people—one that could power a unified admin tool—CRUD operations, reporting, and internal data exploration in one place. In practice, this means account managers configuring advertiser settings, content teams managing hotel information, and operations staff debugging data issues—all through a single interface.
This is the story of how we built that internal gateway and what we learned along the way.
The Solution: GraphQL and Gateway Architecture
Why did we pick GraphQL even though it was mostly used for public-facing APIs? When we looked more closely at its characteristics, the decision came down to a few reasons.
First, GraphQL offered an expressive, easily extensible API format. Its schema-first approach gave us a clear contract with built-in documentation and the ability to evolve the API over time without breaking our admin tool. For internal tooling that would grow organically, this mattered—it made frontend development against the gateway much easier. Building CRUD interfaces against a well-typed, self-documenting API is significantly simpler than wiring up multiple REST endpoints.
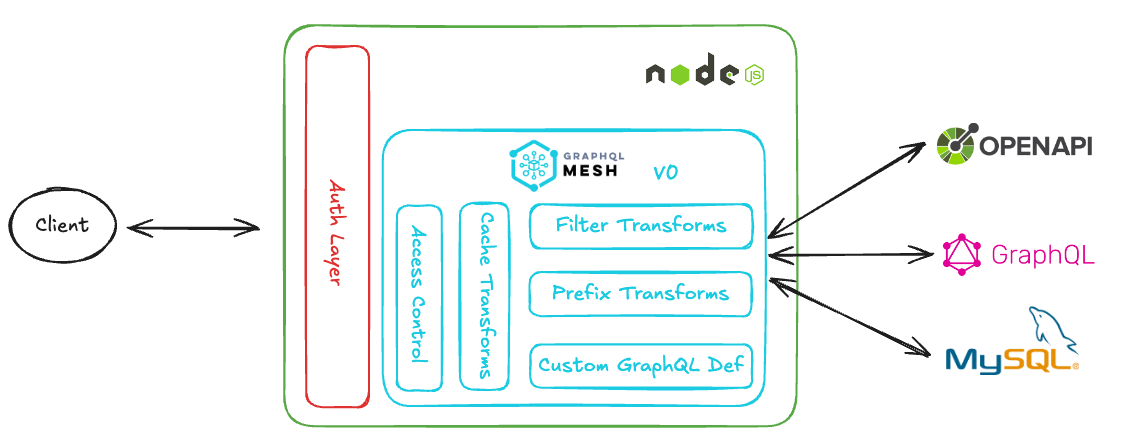
Second, we needed a way to unify diverse sources without requiring upstream changes. Within the GraphQL ecosystem, Federation offers this through collaboratively-designed subgraphs—but that assumes participating services actively adopt GraphQL and coordinate on schema composition. Given the diversity of our internal systems and teams’ priorities, this was not realistic. Back in 2020, we discovered GraphQL Mesh, a framework that could automatically translate existing APIs into GraphQL schemas. OpenAPI specs, gRPC services, databases, even other GraphQL services: Mesh could consume their definitions and generate a queryable GraphQL layer without modifications to the source. Upstream services remain mostly untouched. They continue serving their primary consumers in whatever format they prefer, and we consolidate their data on our end without imposing requirements.
Third, GraphQL’s ecosystem made it straightforward to implement gateway-level features. A GraphQL Gateway naturally centralizes concerns that every API gateway eventually needs: authentication, authorization, rate limiting, caching, logging, monitoring, error handling, etc. These could be handled once at the graph layer rather than being scattered across individual integrations. I touch upon these implementation details below. At the time, GraphQL Mesh v0 offered built-in support or easy extensibility for most of these concerns. Today, one would typically use GraphQL Mesh v1 solely for transforming APIs into GraphQL schemas, paired with a dedicated gateway solution like Hive Gateway—the natural successor to what Mesh v0 provided.
We also saw potential in unifying data entities across services—more of an aspiration than a goal at the time. Even after almost six years, it remains very difficult to achieve in practice. Our graph is primarily focused on connecting and exposing services rather than deeply merging their data models. It remains mostly flat and wide rather than deeply nested with rich entity relationships like a typical public-facing graph.
Key Implementation Details
Schema Composition and Gateway Architecture
Schema composition is handled entirely by GraphQL Mesh through schema stitching. Today, we connect over 15 upstream sources—ranging from OpenAPI services and MySQL databases to existing GraphQL servers—and the number continues to grow. Mesh generates a GraphQL schema from each source definition and merges them into a single unified graph. Adding a new service typically means adding a configuration block and letting Mesh handle the rest.
Mesh also allows us to extend beyond what’s auto-generated:
- Custom resolvers for computed fields or cross-service relationships that don’t exist in any upstream source.
- GraphQL Type extensions to enrich auto-generated types with additional fields—sometimes derived data, sometimes fields pulled from a secondary source.
Caching benefits from this centralized architecture as well. Because all queries pass through a single gateway, we can apply caching rules at the graph layer—per field or per type—without modifying upstream services.
Even though the gateway has enough capabilities to run on its own, we chose to embed it in an existing NodeJS Express server. This allowed us to reuse existing integrations with internal systems: employee authentication, monitoring, alerting, and deployment pipelines. It also gave us flexibility to handle operations that don’t fit the typical GraphQL request-response model—such as streaming file uploads directly to cloud storage.
That said, we deliberately avoided deep customization. The goal was to keep the gateway thin—translating and composing, not implementing business logic. For the most part, business logic stayed in the upstream services where it belonged.
Schema Transforms
The services we connect often expose more than we need—or use naming conventions that collide. GraphQL Mesh provides transforms to shape the raw auto-generated schemas into something coherent for the final consumer.
We extensively use two:
- Filter transforms to exclude internal fields that are irrelevant for the admin tool.
- Prefix transforms to prevent collisions when multiple sources define similar entities.
For example, a Hotel entity might exist both in a raw data storage layer and in a downstream service that handles enrichment and validation—call it HotelContent. Without prefixes, these would clash. With transforms, they become DataStorage_Hotel and HotelContent_Hotel, each queryable for different purposes: one for debugging or even mutating source data, the other for viewing the resolved, validated output.
Access Control
Access control is role-based. The modern approach in GraphQL gateways uses schema directives to declare permissions directly on fields or types:
type Mutation {
updateHotel(id: ID!, input: HotelInput!): Hotel
@requiresScopes(scopes: ["hotel_admin"])
}We still maintain an older pattern for historical reasons: a composer resolver—essentially a higher-order function that wraps existing resolvers and checks roles based on user context before execution. The effect is similar, but the permissions are not declared in the schema itself. Over time, the plan is to migrate to directive-based annotations for better visibility and self-documentation. Composer resolvers might still remain relevant, especially in complex scenarios where dynamic logic is needed.
Audit Logging of User Intent
Our implementation goes beyond logging that a mutation was called—we capture what changed, who changed it, and whether it achieved the intended effect. The approach has a few key characteristics:
- Client-driven context. The frontend admin tool provides rich metadata—change comments, user flow origin, old and new values—that the gateway couldn’t infer on its own, which gives more business context to each change.
- Outcome verification, not just intent logging. Rather than recording “mutation X was called,” we compare actual response values against expected values. This tells us whether the mutation achieved its goal, not just that it ran.
- Batched auditing for related changes. Multiple mutations can be logged together in a single audit entry, preserving the logical grouping of changes.
- Gateway enforcement. Plugins at the gateway layer ensure critical mutations have corresponding audit entries and eventually log events if both mutation and the returned values match expectations.
In practice, the frontend batches mutations and appends a logAuditEvent mutation at the end. GraphQL executes root mutations sequentially, so ordering is guaranteed.
mutation UpdateHotelTranslations {
de: updateHotel(
id: "123"
input: { language: "de", translatedName: "Hotel A" }
) {
id
translatedName
}
jp: updateHotel(
id: "123"
input: { language: "jp", translatedName: "ホテルA" }
) {
id
translatedName
}
logAuditEvent(
scope: "Hotel"
changeReason: "Reported with Task-123"
input: [
{
expectedSuccessPath: "de.translatedName"
expectedSuccessValue: "Hotel A"
oldValue: "..."
newValue: "Hotel A"
}
{
expectedSuccessPath: "jp.translatedName"
expectedSuccessValue: "ホテルA"
oldValue: "..."
newValue: "ホテルA"
}
]
) {
success
errors {
path
reason
}
}
}The pattern has served us well for six years, but it comes with limitations:
- The client must construct audit entries correctly; if the path or expected value is wrong, the audit is wrong.
- Audit requirements are not self-documenting in the schema.
- We may impose a requirement on upstream services: to return the values we need.
- The pattern doesn’t fully work for asynchronous updates. If an upstream service triggers a long-running pipeline, the immediate response may not reflect the final outcome.
A directive-based approach with annotations would solve some of the limitations, but would sacrifice some of the flexibility the admin tool currently has—particularly the client-driven context and fine-grained success verification. Nevertheless, it’s an area for future exploration on our end.
Six Years In
When we started the project, we could not foresee the extent to which the gateway would grow. Over time, maintaining and constantly evolving it taught us things we didn’t expect—and exposed challenges we’re still navigating.
What the Gateway Revealed
One thing we didn’t anticipate: the gateway became a mirror for our internal systems. It also became a lens into internal company processes and operations.
When you stitch together 15+ services from various corners of the company into a single graph, gaps become visible. We discovered data relationships that were assumed but never formalized, and fields that nobody could explain anymore. The process of integrating a service forced us to ask questions that had never been asked—or had been answered years ago and forgotten.
This turned out to be valuable beyond the admin tool itself. The gateway became a forcing function for clarity. If we couldn’t understand how a service worked well enough to integrate it, that was a signal. Sometimes it led to better upstream documentation. Sometimes it surfaced data quality issues. Occasionally it revealed that two teams had been maintaining similar solutions with significant overlap without realizing it. All in all, it felt like we were discovering new knowledge about trivago.
This knowledge accumulation had an additional benefit. Over time, the team developing the gateway became an important voice during technical and architectural decisions across the company. Because we possessed knowledge about multiple systems, their interconnections, and—most importantly—their business domains, we became consultants for other teams looking to build new services or modify existing ones. The centralized internal-facing gateway also brought teams together in ways that hadn’t happened before, fostering a culture of collaboration where previously things were more fragmented.
We also learned that a flat graph with multiple, sometimes “duplicated” entities can work fine for internal use cases—because the distance between frontend developers and backend maintainers is smaller. In the transforms example earlier, we mentioned HotelContent_Hotel and DataStorage_Hotel. Fully merging these into a single Hotel entity with rich relationships remains difficult—and we’ve stopped treating that as a failure. Our consumers are colleagues, often ourselves. We have the context to understand the data model’s limitations. We can decide where to join data: on the client, in the gateway, or by asking upstream teams to improve their APIs. A public-facing graph needs a polished, well-thought-out model because you don’t know your consumers. We do.
In fact, keeping the graph relatively flat makes us more flexible. Internal services iterate fast. By the time we’d fully merge entities the “correct” way, upstream services might have changed their data model again. We’d rather adapt quickly than chase perfection. A flatter structure also simplifies error handling—when one source fails, the impact is isolated, and the frontend can handle partial responses without nested relationships cascading into larger failures.
What Proved Hard
That said, the journey had its rough edges. Four challenges stood out over the years.
Breadth of expertise. The team behind the gateway needs to cover a wide business scope—almost as wide as the company itself—and hold expertise across different technologies. A dataset might be available via an API, a database, or a Kafka stream—which one do you integrate? What’s the source of truth? Why? These decisions require both technical depth and business context. In practice, this meant gateway developers became heavily involved in product management as well. This combination of skills is not easy to hire for or develop.
Environment complexity. Internal APIs often have multiple environments: production, staging, sometimes preview or QA. Combining these into a single meaningful graph is not trivial. Upstream systems interconnect in unpredictable ways, so there cannot always be one unified staging environment. In practice, our staging gateway sometimes connects to production systems and vice versa just to be usable.
This becomes even more complicated at the schema level. Sometimes an entity needs to be present in the graph with both its production and staging variants. Encapsulating and distinguishing these properly is challenging. It raises a question we still grapple with: what does staging mean for the gateway versus staging for the sub-services it connects to? Once a service participates in the gateway, its environment becomes a business detail—because managing internal data and systems is the actual business of the admin tool.
Documentation as original work. Knowledge about internal systems rarely exists in proper documentation. It’s either in people’s heads or scattered across Slack conversations, meeting notes, and code comments—fragments that lack structure or context. Generating documentation with AI or inferring it from existing sources was not enough. Someone had to explore various resources, meet with people, and transfer that knowledge into a structured, written form. We produced technical documentation heavily enriched with business context. It requires significant effort to create and maintain, but it pays off as more services connect to the gateway and the need for shared understanding grows.
Schema registry is a must. We failed to impose a schema registry early in the project. Teams made changes to their APIs for their primary use cases—supporting trivago’s core products—without always informing us. This wasn’t negligence but natural prioritization. Their main stakeholders came first, and our gateway was a secondary consumer.
Currently, the process is more primitive than we’d like. Teams sometimes share schemas via Slack, and we manually add them to the gateway, checking for breaking changes in some cases by hand. It’s not something we’re proud of, and it’s high on our list to improve.
A schema registry integrated into CI/CD pipelines would have caught incompatibilities earlier. The ideal flow: upstream services—whether exposing OpenAPI specs, gRPC definitions, or other formats—would automatically upload their schemas to a central registry as part of their build process. The registry would check compatibility with the gateway, including translation to GraphQL via Mesh, and surface any issues before the upstream PR is merged. This doesn’t necessarily mean blocking deployments. Being a secondary consumer means we shouldn’t slow down core product delivery. But awareness changes everything—it enables follow-up coordination.
Overall, a schema registry would have saved us from deployment risks and runtime surprises. This is something we’d do differently from day one if starting over. Today, we could enhance our existing setup by pairing GraphQL Mesh with a registry solution like Hive Console.
What’s Next: A Foundation for AI Agents?
The unified graph we’ve built over six years—its schema, its connectivity to a large part of the company, and its built-in access controls—could serve as a foundation for AI-assisted internal tooling. A well-typed, self-documenting API with role-based permissions is a natural interface for an AI agent to interact with.
Consider a concrete scenario: an account manager reports that a hotel’s pricing data looks wrong. Today, debugging this means switching between multiple tools and UIs—checking raw data in one dashboard, comparing it against an enriched version in another, pulling up documentation or Slack threads to understand how the pipeline works, verifying advertiser configuration in yet another interface. An AI agent with access to the gateway could follow this same investigative path through a single interface: query DataStorage_Hotel, compare against HotelContent_Hotel, check related advertiser settings, and surface where the data diverges—work that currently takes a human a significant amount of time and context-switching to piece together. Combine that with the human-written documentation we’ve built over the years—rich business context, domain knowledge, explanations of why things work the way they do—and the agent gains the ability to not just retrieve data but reason about it. Protocols like MCP (Model Context Protocol) are emerging to connect AI agents with structured data sources, and a GraphQL gateway fits naturally as the underlying layer.
Pursuing this direction would require revisiting many of the challenges we described—and would likely reveal new ones. Nevertheless, our existing GraphQL gateway feels like the right foundation. It’s early, but it’s the most exciting direction this project could take.
Conclusion
GraphQL gateways don’t have to be about external consumers. For us, the gateway became more than a technical layer—it became a lens into how trivago operates, surfacing gaps, connecting teams, and enabling tooling that would have been impractical to build otherwise. If you have a fragmented internal API landscape and teams building admin tools against multiple backends, this approach is worth considering—and with AI-assisted tooling on the horizon, the foundation only becomes more valuable. The tooling has matured, the patterns are proven, and the benefits extend well beyond the technical.
Looking to use Hive?
Talk to usMore stories
- Real Estate
Hemnet is Sweden’s largest property platform, serving millions of users who browse, save, and search through real estate listings every day. Behind the scenes, a GraphQL API handles the bulk of these interactions, powering everything from listing pages and search results to user accounts and saved properties.
Read full story - Finance
As the company scaled, the need for a robust, flexible, and efficient API architecture became paramount, leading to the adoption of GraphQL with Hive as their central API management solution.
Read full story - Music
Sound.xyz is revolutionizing the music industry by addressing two critical challenges: the concentration of streaming revenue among top artists and the inadequate compensation per stream.
Read full story