
This blog is a part of a series on GraphQL where we will dive deep into GraphQL and its ecosystem one piece at a time
- Part 1: Diving Deep
- Part 2: The Usecase & Architecture
- Part 3: The Stack #1
- Part 4: The Stack #2
- Part 5: The Stack #3
- Part 6: The Workflow
In this series, we had looked at some interesting parts of the GraphQL stack so far with a range of tools, libraries and frameworks from the community. Let us continue the journey in this blog looking at more such tools and services which have created a great impact in the GraphQL ecosystem.
The evolution of GraphQL clients have been really amazing, and I would say, this is one of the great things about GraphQL given its powerful introspection capabilities, being self documenting and also providing ability to extend everything with extensions.
It all started with GraphiQL demonstrating all these back in the day, but then came Playground (which had recently merged with the GraphiQL team to make things even more interesting), Altair and even desktop/web/editor based clients like Insomnia, Postman, Hoppscotch, VSCode Rest Client and the list goes on all proving that the developer experience with GraphQL can be made really better with just some sugar on top.
But, some reasons why thinking about the future of GraphiQL feels really great is cause of the upcoming support for Monaco mode , support for plugins and a lot of amazing features from Playground to now become as part of GraphiQL as part of the transition according to the blog linked above.
Also, embedding a GraphiQL editor is as simple as importing the HTML and related assets as specified in their README.
And while the user experience is made as simple as possible, there are a huge number of components which make it all happen behind the scenes as mentioned in the README and you can have a look at all of them in the monorepo here and here.
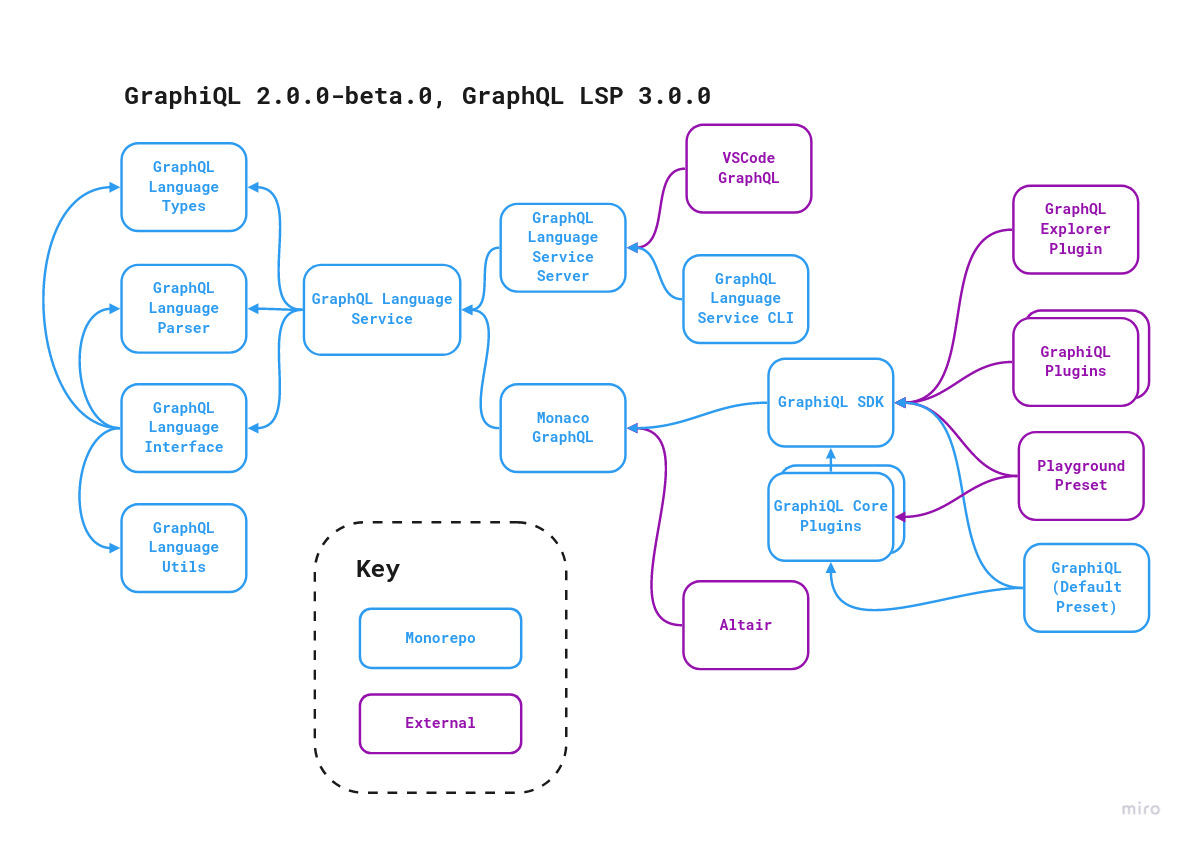
Source: GraphiQL
Codemirror used to be
the interface which used to provide the editor support for GraphiQL, Playground, Insomnia and other
editors in the ecosystem in 1.x which is now being succeeded by the
language service
which takes care of providing a web/desktop IDE experience if you are using editors like VSCode,
Language Parser
which takes care of parsing the GraphQL SDL and operations you write and convert them to GraphQL AST
(If you are curious about how the AST looks, like, you can try going to
ASTExplorer select GraphQL, enter your operation and have a look at the
AST which is what the final representation will look like) and so on becoming a platform for not
just GraphiQL but the entire editor ecosystem.
Starting with GraphQL or GraphiQL may actually have a learning curve for beginners since it takes a different approach to dealing with data. And even after people settle down with GraphQL, some people do feel like life was better for them when they were using something as simple as REST or GRPC.
This is where tools like GraphiQL Explorer play a major role where all their queries and mutations can be constructed automatically just by checking all the fields you need from the schema.
This workflow feels intuitive since it is as simple as checking all the fields you need in your client. You can read about how Onegraph solves this problem here
It is just a React component which you include with your GraphiQL instance and the rest is history.
The next beautiful tool I would talk about here is the GraphQL Voyager. In fact, this is the first tool I used when I was new to GraphQL few years back, and it drove me nuts seeing the potential of what GraphQL can do.
The reason this is great is because, this leverages the complete power of introspection from GraphQL. You get to see all the entities and how they are related, search through the schema and also browse the docs
Source: GraphQL Voyager
And today, GraphQL Editor takes this one step further allowing you to view, edit, browse all the entities and hierarchy making it really a great tool for anyone who wants to quickly work through the schema.
One important thing which GraphQL Spec did not discuss is a way to transmit files over the wire when using GraphQL. This is where GraphQL Upload comes in. While not an official spec from GraphQL foundation, Jayden had done a great job to put together a multipart spec to address exactly this problem.
GraphQL Upload is the library which provides a great implementation of this spec with an ability to work with various frameworks. One thing to remember is that, while GraphQL Upload definitely does the job and works well over a significant scale, you might want to stick to HTTP for higher production workloads because of the reasons outlined in this blog.
And if you are using something like a GraphQL Gateway with either federated GraphQL or stitching, you might want to make sure that you don't overload the gateway transmitting files creating probable bottlenecks which can affect the rest of your requests. So, try striking a balance since GraphQL need not be a solution for every problem.
Subscriptions are a powerful part of GraphQL allowing you to track all the operations happening with the data in near-real time but this mandates the use of a protocol like websockets or use something like Server Sent Events (SSE).
While subscription-transport-ws from Apollo initially started off this journey, it is not actively maintained and GraphQL WS by Denis definitely is a great replacement to that having no external dependencies and having the ability to work across many frameworks.
But do remember that, websocket might loose its lead in the future especially with the introduction of HTTP/2 and HTTP/3 as mentioned here while definitely here to stay. But this wouldn't affect GraphQL in any way since its transport independent.
Also note that subscriptions are not the only way to do real time communications in GraphQL. There are also things like Live Queries with great libraries like this from Laurin which you can use
While Schema Stitching was initially advocated by Apollo with introduction of many helper functions in GraphQL Tools, their direction did change soon after hearing a lot of feedback from their customers and took their call to introduce Apollo Federation. You can read their reasoning in this blog but this does not mean that stitching has lost its relevance especially with the introduction of Type Merging.
Apollo Federation does a great job especially when you use it with the rest of the ecosystem from Apollo like the Apollo Studio. Apollo Stack does offer a lot of features which might be relevant to working with a data graph in an organization starting from providing a registry where you can upload parts of the combined schema from all services, version control the changes to your schema validating breaking changes, providing metrics regarding all the clients consuming the schema, tracing of all operations, multiple variants to manage multiple environments, alerting across multiple channels, and a CLI to work with all of these.
And this can definitely help teams who want to maintain their own part of the schema.
Federation comes with its
own specification and directives
as part of it which helps people to define all of the relations between multiple GraphQL entities so
that the Apollo Gateway can
combine them all together without having to modify the GraphQL gateway and also functions like
__resolveReference which helps in resolving an entity with its reference as specified by the
directives.
The Apollo CLI when combined with Federation does come with a lot of helpers to take care of things like pushing the schema, listing the services in the studio, doing codegen and so on though I am not currently sure why they are rewriting it again to Rust apart from the reasons as suggested here.
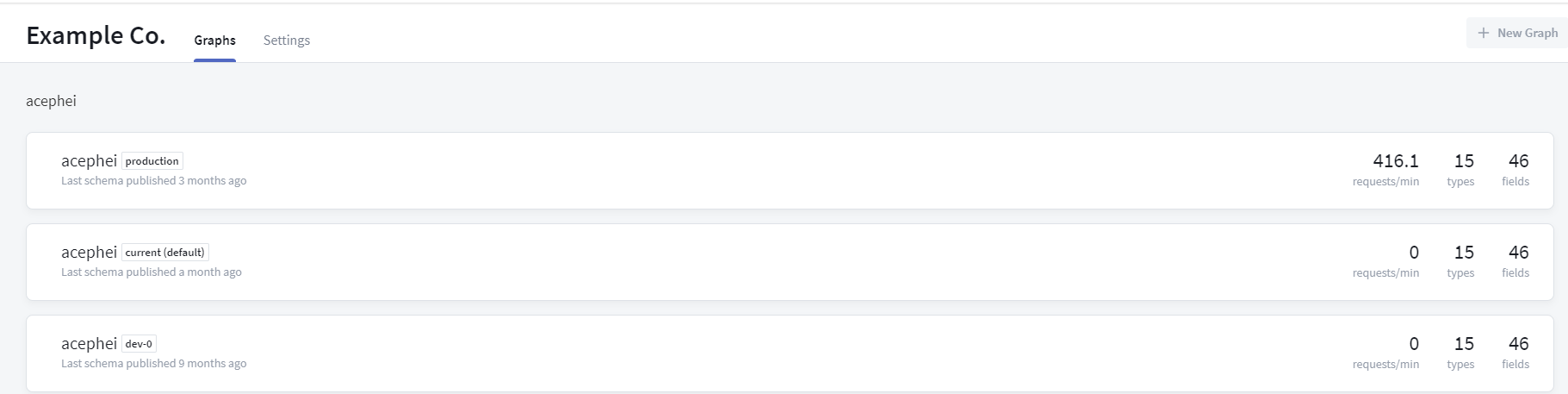
Let's quickly look at how Apollo Studio lets you manage the schema
This is how you maintain multiple Data graphs in your organization across environments
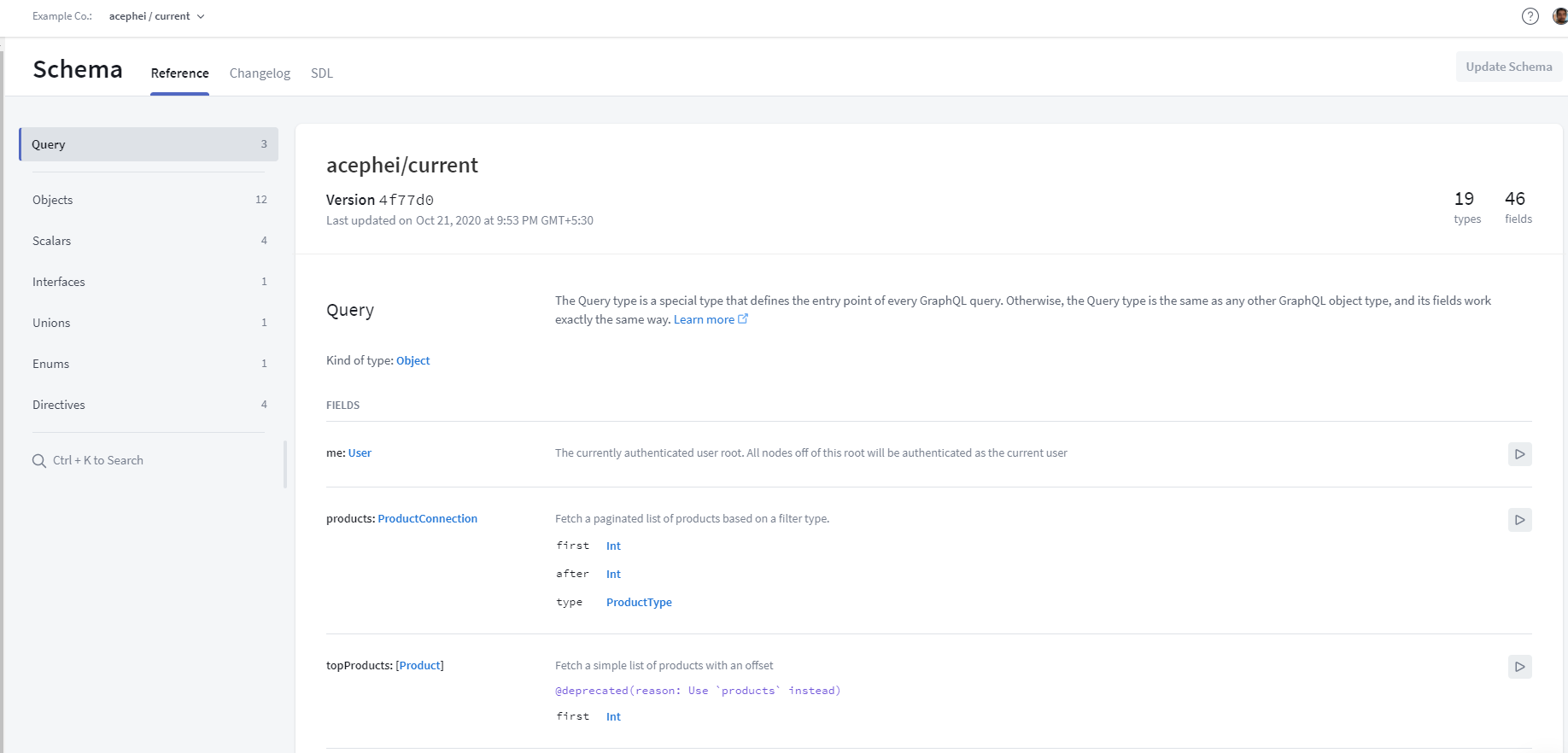
Browse through the schema, its types, documentation and so on
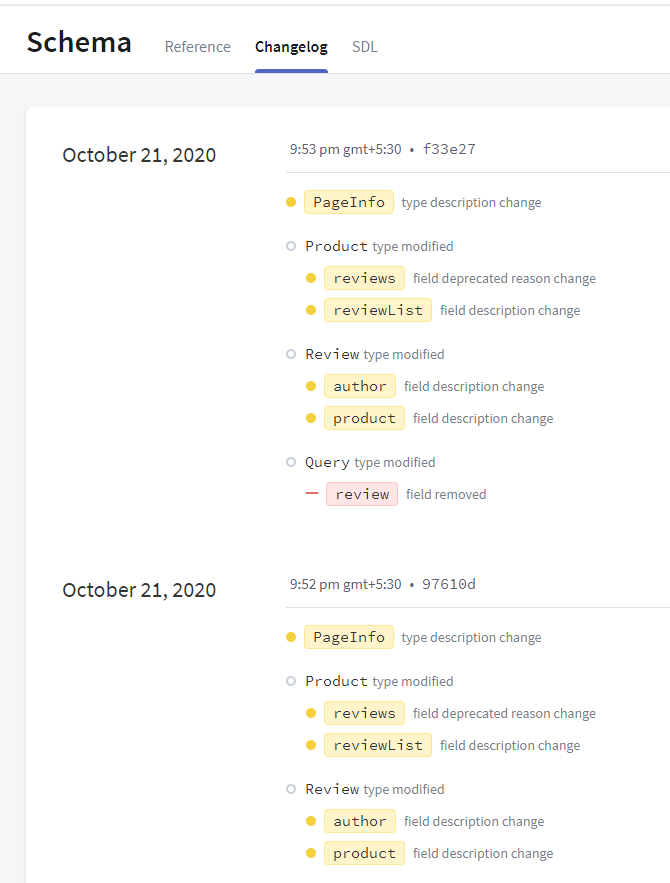
Track the changelog of your schema over time
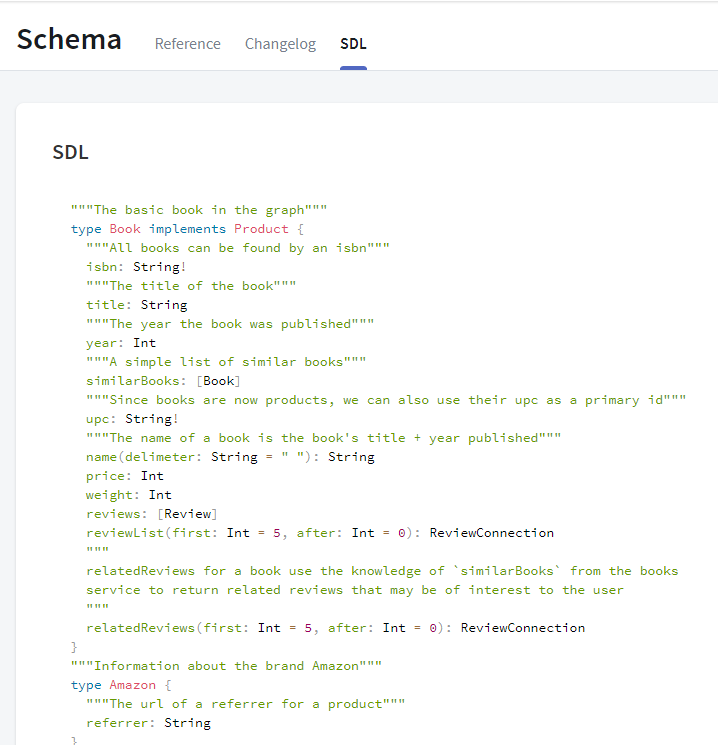
Browse through the SDL of your schema
Execute GraphQL operations against your schema
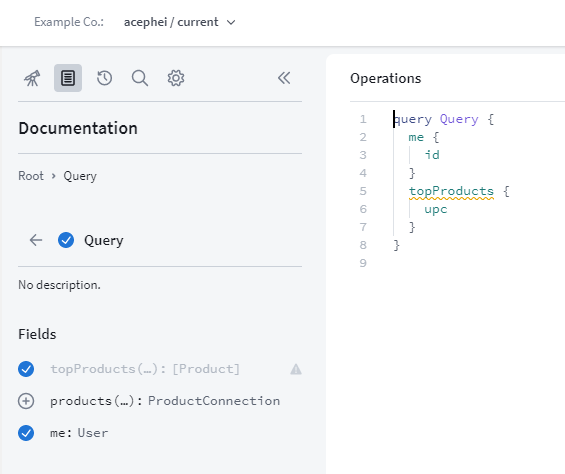
and does offer a lot more especially when you are a paying customer.
NOTE: Federation with Apollo Server does not support subscriptions yet, and you might want to stick with stitching if you are looking for subscriptions support or switch to some other server like Mercurius since it does allow subscriptions over federation.
Gatsby is a static site generator powered by React, GraphQL and a lot of plugins contributed by the community which helps you sites simply by pooling in data from multiple different sources in multiple different ways, and it really popularized the idea of doing this all via GraphQL. If you want to know why and how Gatsby uses GraphQL, you can give this a read. And while Gatsby does offer both Server Side Rendering and Static Site Generation, I would say it all boils down to your use case.
While Gatsby did popularize the idea of using GraphQL for static sites, there are a lot of other static site generators out there like Eleventy, Jekyll, Hugo, etc. and I find myself personally aligning towards Eleventy because of quite a few reasons which may not be right for this blog. But if you are curious, you can read blogs like this and this which gives a comparison.
Opentelemetry is the new standard for instrumentation (especially after Open Tracing and Open Census merging together) and this makes things really amazing for people since there were quite a few overlap before in between them which can now be avoided to bring about a powerful tracing standard.
Opentelemetry is not specific to any language or implementation, and you can find all the amazing projects from Open Telemetry hosted here
Now, the exciting thing is that there is now a reference implementation to the same using GraphQL which you can find here and also an example to help you out with the same here
This when used with Jaeger, Zipkin or Tempo can provide you with Traces for your GraphQL operations which you can track across your resolvers. Do note that it is not advisable to be turned on for everything since it has a performance overhead.
This can give you a context on how your data and context flow irrespective of your architecture in your resolvers and functions.
Faker.js has been a great project to quickly generate mock or sample data providing various types of entities inbuilt. For eg. you can generate random addresses, images, URLs and so on, helping you to quickly test out your application without relying on the server or the backend to hold data.
This has become even more amazing with GraphQL Faker since it allows you to use all the great things
which Faker provides you with directives. Just define what data you want a specific field to
generate by specifying the relevant directives and GraphQL Faker can actually generate all the data
for you using Faker.js
Source: GraphQL Faker
If you are using @graphql-tools you can also use faker.js directly and combine it with
Mocking to get similar results, but without the need to
change your SDL.
While there are a lot of other tools we can discuss, the GraphQL ecosystem is huge and this pretty much has no end. But I do presume that these are all the tools you mainly need to start your GraphQL journey and leverage the ecosystem in the best way possible.
But with this the GraphQL journey is still not over. We will continue the next blog discussing a few more interesting things as part of the GraphQL series.
Is there anything you would like to see me address in this series? Do let me know, and we can probably do that in an another post.
If you have any questions or are looking for help, feel free to reach out to me @techahoy anytime.
And if this helped, do share this across with your friends, do hang around and follow us for more like this every week. See you all soon.