
Summary
- Building a GraphQL servers with Cloudflare Workers is now at a "production ready" stage
- Database connection over TCP is also works well (although it's beta, so there might be some eage cases)
- Node.js compatibility with Cloudflare Workers is not perfect, so it is better to use a Web Server Framework that was built to support CF Workers
Motivation
Cloudflare Workers is often used as a proxy on a CDN or as a backend for rendering Remix or Next.js.
When it comes to APIs for retrieving and updating data from the front end, most of the time I think it is necessary to set up and build a separate backend server. I myself often set up a backend server in Node.js in this pattern, and when I do so, I choose Cloud Run as my first choice because it is easy to set up. Cloud Run itself is a great service, but it is human beings who become even more greedy.
- Deployment speed needs to be faster.
- I want to keep the price a little lower.
The former is a container service, so it requires "container build" and then "container replacement", but "container replacement" as well as "container build" takes a lot of time there. No matter how fast you do these two, it will take 5 to 10 minutes. The latter means minimizing cold standby (startup speed) and asynchronous means using the minimum number of containers, Always CPU, etc. That will cost a certain amount of money. I still think Cloud Run is cheaper, though.
A Note about Database Connections
I believe that Cloudflare Workers can fulfill these requests, but when its necessary to set up an API server, a database connection is also required. if you are using a database that can communicate via PostgREST API such as Supabase, Cloudflare Workers can connect to the database via the PostgREST API, but making a direct connection to the database has not been possible until now. However, this situation has changed with the recent announcement of support for connections over TCP.
https://blog.cloudflare.com/workers-tcp-socket-api-connect-databases
I think that just because it is possible to connect via TCP, the advantage of the edge location is lost a bit, because when an application that runs on the edge, connects to a database in another location to retrieve data, there is an overhead for that connection. So I'm waiting with anticipation for the Cloudflare D1 to come out in the future, as it will maximize the advantages of that location.
Another point is that running your GraphQL server on edge means you can also store its cache on edge, which would means faster response times.
Cloudflare Workers is as great a service as Cloud Run, so the purpose of this article is to actually run it as a backend API server on top of Cloudflare Workers.
Architectures
Let's proceed under the assumption that the backend API will be prepared as a GraphQL server, and I will write down what tools I used to build it.
Cloudflare Workers
https://workers.cloudflare.com
The first assumption is this. The choice of Cloudflare Workers as a service or runtime narrows the technologies that can be used in an application. Therefore, it is written as an assumption.
Web Server
https://the-guild.dev/graphql/yoga-server
Many existing/older Web Servers have limited support for Cloudflare Workers. That's because they were built at a time to only support Node.js.
Newer Web Server frameworks like feTS or Hono are modern and have better support for Cloudflare Workers.
In our case, we will use Yoga Server because it supports GraphQL and it also uses the same powerful @whatwg-node library as feTS, in order to support any Javascript runtime, including Cloudflare Workers.
GraphQL Schema Builder
This is a preference. There are two patterns: "schema-first" and "code-first." I prefer "code first" and have the schema automatically generated from the code, and I have chosen Pothos, which I have used and like when using Prisma.
ORM (Query Builder)
https://github.com/kysely-org/kysely
Unfortunately, even Cloudflare Workers, which can now connect directly over TCP, does not work with Prisma. I won't go into details here, but Prisma has two major processes, client and engine, but there is no mode provided to run the engine part on Cloudflare Workers. This is why it does not work. The options are Kysely or Drizzle, both of which can be run in Cloudflare D1, so if you want to change them in the future, you can do so in either case. However, the TCP connection that was announced this time is available using a library called pg, so we will choose Kysely to connect using this library. (For the sake of accuracy, Kysely is not an ORM, but a query builder.)
Database Migration
Database is a very sensitive subject, so we want to use a stable database. So for migration, it uses Prisma. There is another reason to use Prisma. If using Prisma, you can use prisma-kysely to automatically generate types for Kysely.
Build a GraphQL Server
From here, start writing the actual code. By the way, the finished product is in this repository. If you want to see only the finished product, please refer to the repository.
Create Cloudflare Workers
Create them using c3, which was recently announced.
npm create cloudflareYou can choose a template, but currently, no matter what you choose to create GraphQL, there will be something in the way, so choose something as close to a blank state as possible to build it.
This will create Cloudflare Workers that output "Hello World".
Create a GraphQL API
Build a GraphQL API using GraphQL Yoga. First, install the necessary libraries.
npm install graphql graphql-yoga @pothos/coreCreate a schema with a Query that will be used as a sample.
import SchemaBuilder from "@pothos/core";
export const builder = new SchemaBuilder({});import { builder } from "./builder";
builder.queryType({
fields: (t) => ({
hello: t.string({
resolve: () => "world",
}),
}),
});
export const schema = builder.toSchema();Load the created schema and create a GraphQL endpoint with GraphQL Yoga.
import { createYoga } from "graphql-yoga";
import { schema } from "./schema";
// Create a Yoga instance with a GraphQL schema.
const yoga = createYoga({ schema });
export default {
async fetch(
request: Request,
env: Env,
ctx: ExecutionContext,
): Promise<Response> {
return yoga(request, ctx);
},
};To verify that the created GraphQL server is working, start the server with the following command.
npm run startIf you access http://localhost:8787/graphql in a browser, you can open the Playground where you
can run GraphQL.
query {
hello
}
Create Database Schema
Create a schema for the application to read into the database. Install Prisma and the necessary libraries around it, since the migration is supposed to use Prisma.
npm install -D prisma prisma-kysely
npm install kyselyCreate a schema for the database with a User model by using Prisma.
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator kysely {
provider = "prisma-kysely"
output = "../src"
fileName = "types.ts"
}
model User {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
name String?
email String
}The User model is important, but what is important this time is the generator kysely part. This
is where prisma-kysely outputs the database type file for kysely when database migration is
performed. In this case, the definition is written in the file path src/types.ts. Execute the
following command to output the database type file for database migration and Kysely.
npx prisma migrate devCreate Connections to the Database
Next, writing the code to connect to the database created. The database is assumed to be PostgreSQL, and further libraries are required to connect to it, so we will install them.
npm install -D @types/pg
npm install pgWriting the code for the connection using the installed pg.
import { Kysely, PostgresDialect } from "kysely";
import { Pool } from "pg";
import type { DB } from "./types";
export const connection = () =>
new Kysely<DB>({
dialect: new PostgresDialect({
pool: new Pool({
host: "localhost",
database: "postgres",
user: "postgres",
password: "password",
}),
}),
});There is one important piece of code here. It is slightly different from what is written in the Kysely README.
- export const db = new Kysely<DB>({
+ export const connection = () => new Kysely<DB>({My code is defined in a function and each call is an instantiation of Kysely. This is the intention.
The reason is that when connecting over TCP from Cloudflare Workers, TCP disconnects on a
per-request basis, so I need to make a connection to the database on a per-request basis. Kysely
uses something called Pool in the pg it uses for connections, which does connection pooling.
Kysely also only accepts PostgresPool connections, so this is what it does. connection pooling is
simply explained as defining multiple connections from one application to a database, and using
those connections within an application. However, this connection pooling is incompatible with the
Cloudflare Workers specification that TCP connections are broken after each request. In other words,
when a second request is received, the connection object is already connected, but because
Cloudflare Workers' TCP connection is broken, it cannot connect to the database and an error occurs.
So the code dares to instantiate Kysely in order to reconnect. The following configuration is
required for pg to work on Cloudflare Workers.
node_compat = trueIf you do not enable this option, pg will not work.
https://developers.cloudflare.com/workers/wrangler/configuration/#node-compatibility
Create GraphQL Schema
Finally, write the GraphQL code to fetch data from the database and return it to the client. Some of
the code was suggested by
hayes, the author of Pothos, while I was working on this article.
export * from "./User";import { AllSelection } from "kysely/dist/cjs/parser/select-parser";
import { builder } from "../builder";
import { DB } from "../types";
export const UserType = builder.objectRef<AllSelection<DB, "User">>("User");
UserType.implement({
fields: (t) => ({
id: t.exposeID("id"),
name: t.exposeString("name", { nullable: true }),
email: t.exposeString("email"),
initial: t.string({
nullable: true,
resolve: (user) => user.name?.slice(0, 1),
}),
}),
});export * from "./User";export * from "./query";import { builder } from "../../builder";
import { connection } from "../../context";
import { UserType } from "../../models/User";
builder.queryFields((t) => ({
User: t.field({
type: UserType,
nullable: true,
async resolve() {
const db = connection();
await db.selectFrom("User").selectAll().executeTakeFirst();
},
}),
}));import { builder } from './builder'
builder.queryType({
fields: (t) => ({
hello: t.string({
resolve: () => 'world',
}),
}),
})
+ export * from './models'
+ export * from './resolvers'
export const schema = builder.toSchema()As you can see from the connection() of the resolver, this is where the connection to the database
is established. In a real application, it is better to establish a connection in the GraphQL Yoga
Context and use it for each resolver, instead of establishing a connection for each resolver.
(Creating countless connections puts a load on the database.)
However, it is better to be creative in terms of database connections. Even if you establish one connection per request, the number of connections may grow if you use serverless autoscaling like Cloudflare Workers. If this happens, the database will be overloaded, and in the worst case, the database may go down. Therefore, it is recommended to use a connection pooling tool such as PgBouncer for PostgreSQL.
Verify That It Works
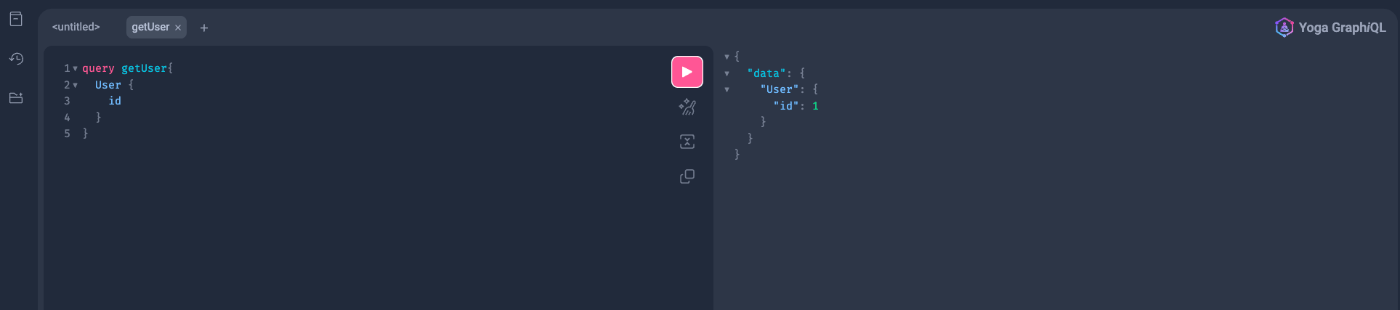
Finally, run the application, execute the next Query, and if it returns the value successfully, you are done.
query getUser {
User {
id
}
}
Conclusion
Although it took some time to identify the connection error by connection pool, building a GraphQL API on Cloudflare Workers is now within feasible limits. Thanks to the help of various libraries, including GraphQL Yoga, I was able to build this API. I think Cloudflare Workers, together with Yoga, can be used to build a fast, production ready GraphQL servers.