
This blog is a part of a series on GraphQL where we will dive deep into GraphQL and its ecosystem one piece at a time
- Part 1: Diving Deep
- Part 2: The Usecase & Architecture
- Part 3: The Stack #1
- Part 4: The Stack #2
- Part 5: The Stack #3
- Part 6: The Workflow
In the previous blog, we had started going through "The GraphQL Stack" that we use at Timecampus going through various libraries and tools like VSCode, GraphQL Config, VSCode GraphQL, GraphQL ESLint, GraphQL Inspector, TypeScript, GraphQL Helix and GraphQL Codegen. In this blog, we will continue our journey exploring from where we left off.
Before we continue, one thing I have to say is that the GraphQL ecosystem is so huge and growing that it is not feasible to look at everything available out there in this GraphQL series, but one thing we are sure of is that, this can indeed put you a few steps ahead in your journey with GraphQL and its ecosystem. With that disclaimer, let's start.
As we have discussed before, GraphQL does act as a single entry point for all your data giving a unified data graph which can be consumed by any client which is really powerful. But this does not mean that you have to mix up all your code in one place making it really difficult to manage.
As people have already found, both Microservices and Monolithic architectures comes with its own set of advantages and challenges and what you go for completely depends on your use case, the scale you need, your team and talent pool.
But this does not mean that you should not keep your application non-modular irrespective of the architecture you go for. Having clear responsibilities, separation of concerns and decomposing your application into modules gives you great flexibility, power and makes your application less error-prone because you just do one thing, but you do it well.
Now, this is where GraphQL Modules really comes in. Yes, you can have your own way of organizing the code, your own way to pull in the schemas, your own set of tools and so on, but you don't have to reinvent every wheel there is.
It helps you decompose your schema, resolvers, types and context into smaller modules with each module being completely isolated from each other, yet being able to talk to each other. And this becomes even more powerful as you scale since it comes with concepts like Dependency Injection allowing you to specify your own providers, tokens, scope and so on.
NOTE: GraphQL Modules overrides the execute call from graphql-js to do all its work. So, make
sure that the GraphQL server you use allows you to override it.
At Timecampus, we use a microservices' architecture, and every microservice is essentially a monorepo (PNPM Workspaces) by itself covering a specific Domain. For instance, this is how portion of my directory structure looks like. If you notice, I am able to split every Microservice into multiple modules like this which allows me to manage the code better.
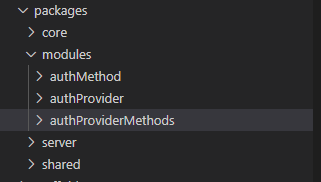
And this is how a simple provider looks like. If you notice, this makes it very simple to comprehend. The convention I use is that, I try to group CRUD operations into a single module but it need not call for a separate microservice all by itself.
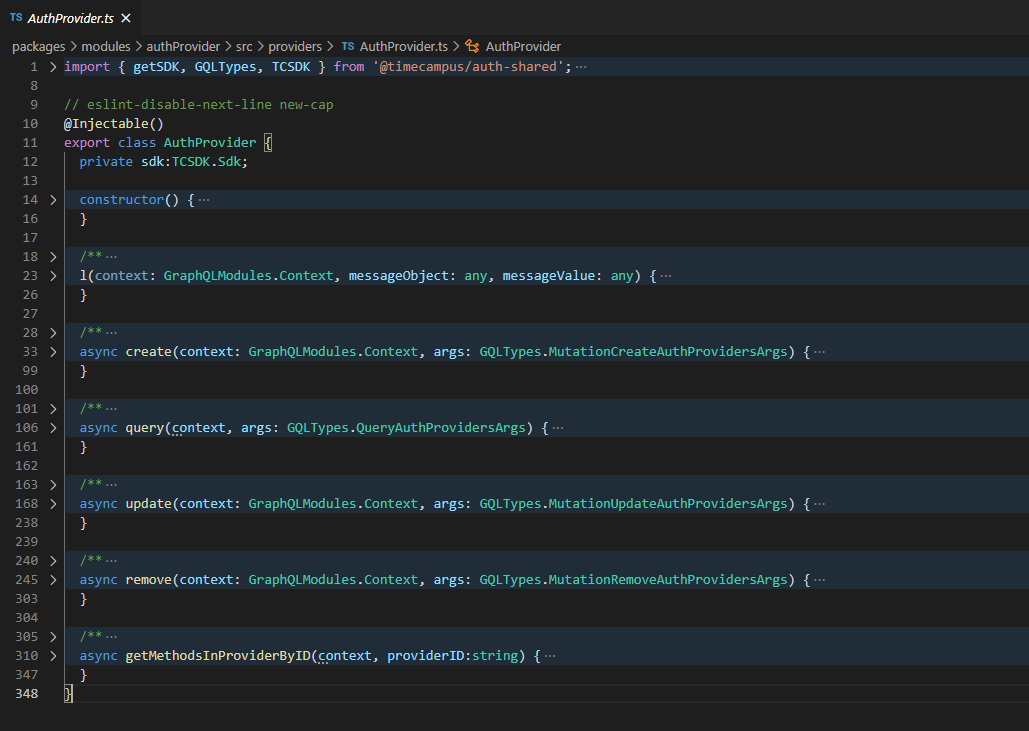
And your Mutations become as simple as this, calling the injector, doing the operations and returning the results:
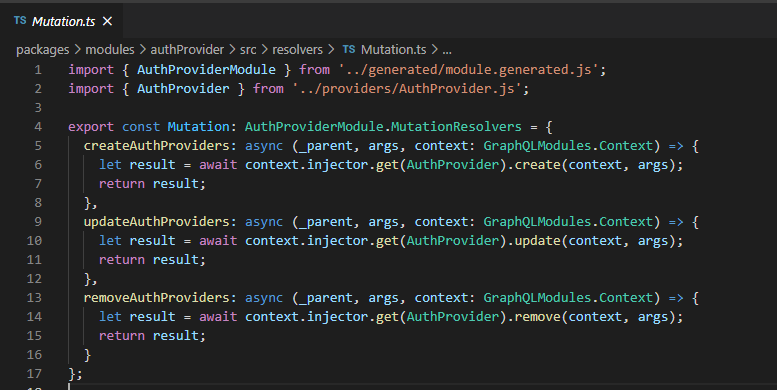
And finally all you have to do is compose the schema and resolvers from all the modules in your server giving a unified GraphQL endpoint you can use.
Now, this becomes even more powerful if you use the GraphQL Modules Preset with Codegen since it essentially also splits your types and generates types for each GraphQL Module making things even more organized and isolated.
There is a lot more that we can explore, but I will leave it at this.
What if you can use GraphQL to do all your operations even when your backend systems, datasources and the services do not understand GraphQL natively and without spending time converting them to GraphQL endpoints? And what if you can aggregate and mesh all of them together with GraphQL? This is where GraphQL Mesh really comes into picture.
GraphQL Mesh acts as an abstraction layer which can interface with multiple different types of backends like REST, SOAP, GraphQL, GRPC, OData, Thrift and even databases like MySQL, Neo4j and so on as documented here.
All you need to do is provide a config file .meshrc.yaml and it will generate everything for you
and the execution engine will take care of converting your GraphQL queries to native backend
specific queries.
Think of GraphQL Mesh like a universal ORM not limited to just databases but any data source or service which produces data and has an execution layer for performing operations on them.
For eg. you can pass in your OpenAPI spec, and GraphQL Mesh will generate all the necessary things for you to provide a GraphQL schema which you can use.
At first, I had to think a bit to see whether GraphQL Mesh is relevant to me, cause my stack completely uses GraphQL natively anyway (including my data source Dgraph which supports GraphQL Natively) and hence was not sure if it suited my use case.
But the more I thought about it, I started seeing GraphQL Mesh as an abstraction layer which will make my stack future-proof irrespective of all the data sources or backends I may add in the future. And the beauty of it is, there are a lot of ways in which you can use the Mesh (as a separate service, as a SDK with your service or as a gateway).
I personally use GraphQL Mesh as a SDK with my services to access the backend data sources running GraphQL thereby avoiding any bottlenecks if any. And the added advantage you get here is that it makes all the operations you do fully typed.
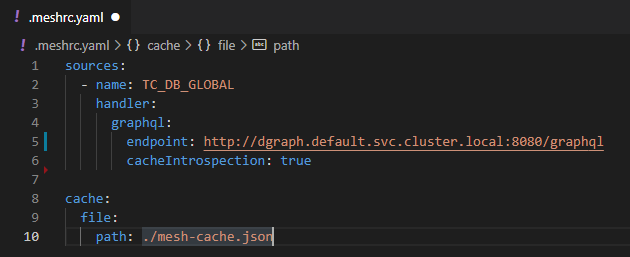
Since I am just in the initial phases of development, this is how my .meshrc file looks like where
I interface with Dgraph with GraphQL Mesh
And when I have the SDK generated with GraphQL Mesh, all I have to do is just use the methods the SDK providers me (based on the GraphQL Mutations and Queries I have provided to it as inputs) like this:
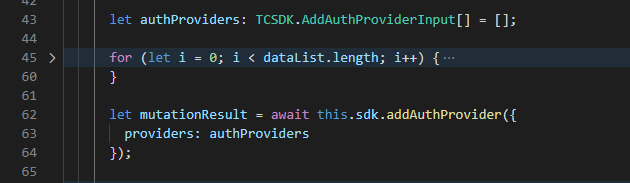
Which makes it really powerful to use without worrying about what happens underneath. While there is a lot we can talk about GraphQL Mesh as well, I will leave it at this for now.
When you talk about GraphQL, one simply cannot forget GraphQL Tools irrespective of the architecture or stack you use. Initially developed by Apollo and then taken over by The Guild, GraphQL Tools provides you a very powerful set of utility functions to work with GraphQL which you can use in your services irrespective of whether you are using something like Apollo Federation or Schema Stitching.
It provides you a lot of utility functions which can help you do things like loading a remote GraphQL schema, merge schemas, mock schema with test data, stitch schemas together with either Type Merging or Schema extensions, enables you to write GraphQL schema directives and the list goes on.
And since it is available as scoped packages @graphql-tools you can just import only the modules
you want and use it without adding any bloat.
The reason GraphQL Tools shines is because, it stops you from reinventing the wheel, helping you focus on the other things which really matter the most in your journey with GraphQL. For eg. if you see below, I use the functions from GraphQL Tools extensively when I do operations with my schema like this:
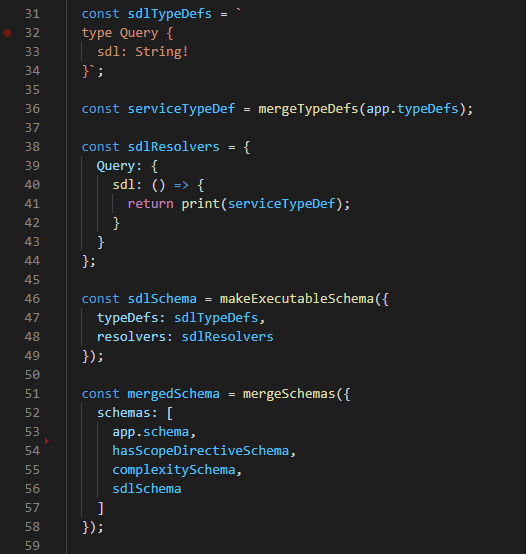
And it also helps me write my own directives like this:
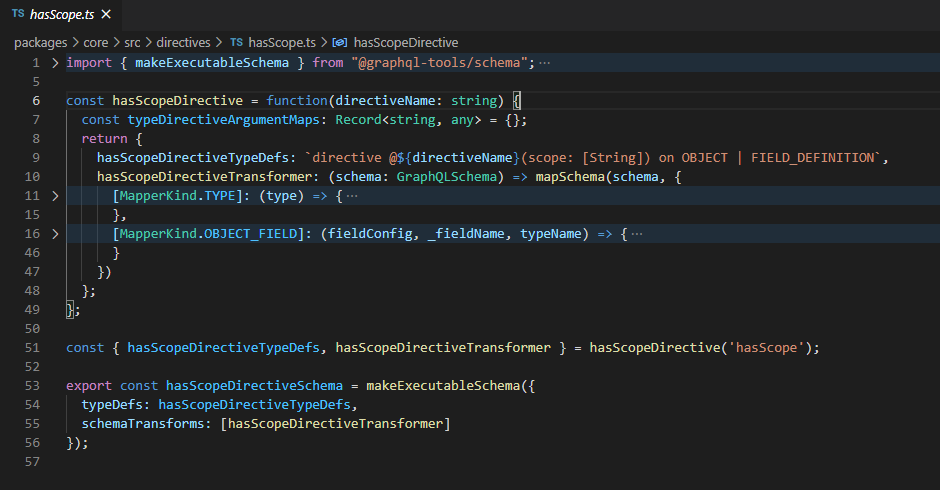
And since I have recently moved from Federation to Stitching, I am also starting to use Typemerging from GraphQL Tools to have my GraphQL Gateway setup as well like this:
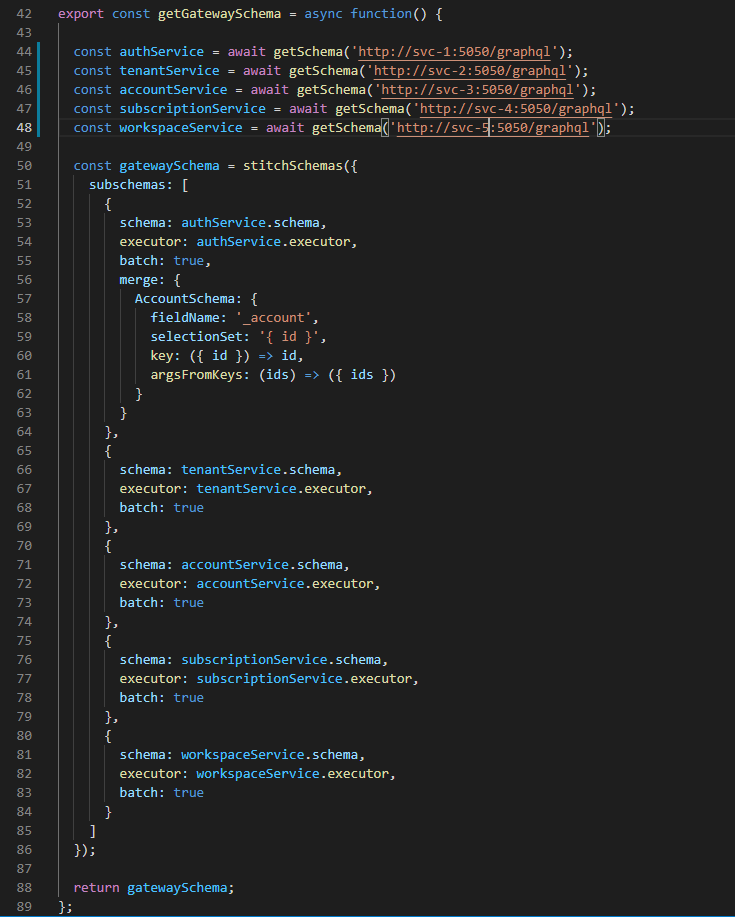
If you are new to schema stitching with Typemerging, I would recommend you check out this repository from Greg where he does a great job of explaining all the concepts.
Typed Document Node holds a special place in my heart cause it was only after coming across this project that I started understanding the power of marrying GraphQL and Typescript together (I had ignored Codegen and all the related tooling before coming across this since I did not understand the importance of it back then).
Typed Document Node does a simple job of converting your GraphQL documents to Typescript DocumentNode objects irrespective of whether it is a query, mutation, subscription or fragment. You can have Codegen generate all the Typed Document Node types for you when you work.
And the reason it is really good is cause, it works well with other libraries like @apollo/client
where you can pass a TypedDocumentNode object generated from your GraphQL operations and the results
will also be fully typed, thus helping you to stop worrying about manually typing your GraphQL
requests.
For eg. this is how I use TypedDocumentNode to have all my GraphQL operations typed when calling
@apollo/client/core in my app.
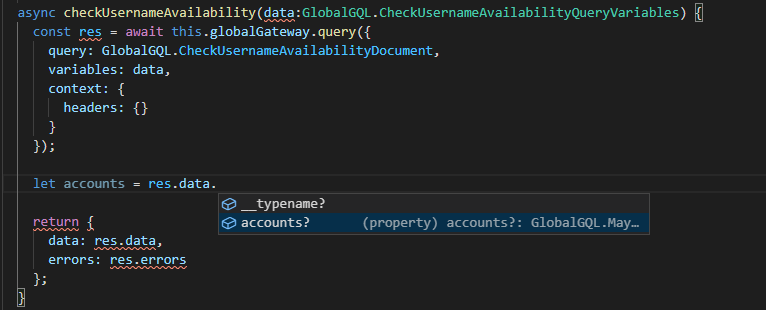
All I had to do is pass the document which was generated and if you notice, even my response is fully typed.
And this is how the generated Document Nodes look like:

Initially I had it running on both the server and the client side but then removed it from the server side since the SDK from GraphQL Mesh was already doing this job for me.
There are also plugins like
TypeScript GraphQL-Request
available when using Codegen which generates an SDK out of GraphQL operations. While I haven't tried
it, I did not opt for it cause I did not want to get coupled to the graphql-request library, and
also this was fitting my use case pretty well.
While Dgraph is not necessarily relevant to anyone and everyone and definitely not for legacy systems, it is of real relevance and significance for us as we work on Timecampus. Dgraph is a scalable and distributed Graph database written in Golang which understands GraphQL natively (while it also has its own query language as well called DQL which is a modification of the GraphQL spec to support database specific optimizations).
As I was building the product, I started off with Postgres with Prisma as my ORM. But as I thought more and more and was writing code, I started noticing a few things.
- All the entities were increasingly getting connected to each other to various kinds of relationships
- Initially I was paranoid, and I had a single Postgres database instance for every microservice following the microservices' architecture conventions, and thus I was left with isolated pools of datasets which led me to manually do a lot of cross-service calls to get data from the other databases in case I wanted to relate them
- I had to clearly know which database instance had a respective schema before even making the call from a service. Hence, things were no longer an implementation detail
- Since I was using Prisma with Postgres (and believe me, Prisma was really amazing to work with), I also had to manage things like Migrations, rolling them back and forth and also do this in the CI/CD pipelines which was adding more complexity
Now, there were a lot of other challenges I was facing other than this, but a few things I quickly realized is that:
- Almost all the data is connected in some way or the other (or at least the majority was)
- Splitting databases to multiple isolated instances per microservice was just adding more and more complexity and the effort was not worth according to me
- A database like Postgres (or even other like MySQL, MSSQL) was not originally designed for a microservices-like architecture (while it definitely works well with it). This makes things like horizontal scaling across multiple nodes difficult to do (while definitely possible with hacks)
- Also, since I ran my entire stack on Kubernetes, I was also looking for a database with Cloud Native support
While I was aware of Graph databases before, a lot of the Graph databases are meant just for storing the edges and vertices (i.e. the relationships between various nodes) and traversing through them but does not have support for storing the data in itself for which I have to opt in for another database to read/write the data. This adds a lot of complexity to everything and you have to keep both in sync as well which makes it really hard to do.
Now, Dgraph solves all these problems (and the awesome part as I already told you are that it supports GraphQL natively which gives me the ability to use all the GraphQL tools with it) .
While they also offer a hosted solution called Slash GraphQL, I opted in for hosting Dgraph Open Source on my own since I wanted to support any environment be it hybrid cloud or on premise, wanted to have the data as close to me as possible to offer compliance.
Since it exposes a GraphQL endpoint, I also run the Mesh SDK/Codegen on it, and it gives me completely typed database operations with the SDK as I mentioned above.
And the only tool I need to interact with it is a GraphQL client like Insomnia or VSCode Rest Client (While it does expose its own client called Ratel for doing DQL operations and managing the database). Moreover, the database schema is nothing but a GraphQL schema. So, I had no learning curve as well.
And another beautiful thing I liked about it is that, I need not worry about scalability anymore since it can be horizontally distributed, across multiple nodes or containers in my Kubernetes Cluster and scaled up/down, and it can handle everything exposing a single GraphQL endpoint without me having to setup a single database per microservice.
A single Graph Database instance per microservice did not make sense for me since it will effectively split the Graph into multiple pieces and the whole point of having a completely connected database graph would be lost.
Also, the feature set was quite promising when comparing other graph databases and the benchmarks were also quite promising when comparing the likes of Neo4j, but there is definitely a counter argument for that.
But the reason I find Dgraph appealing more is cause the underlying store is Badger which is made using Golang and hence does come with its own set of advantages and performance gains. On top of this, Dgraph is not the only store which uses badger which makes it even more exciting to use.
Disclaimer: I don't have experience running Dgraph in production (since we are on our way to launch), but there are definitely others who have done it.
Now the reason, I added Dgraph to this stack was that Dgraph offers a great GraphQL native solution for databases. But if you are looking to go for Neo4j, it does offer a GraphQL adapter too.
Well, the discussion doesn't end here and there is a lot more we can talk about with respect to GraphQL and its ecosystem. We will continue in the next blog post. Hope this was insightful.
If you have any questions or are looking for help, feel free to reach out to me @techahoy anytime.
And if this helped, do share this across with your friends, do hang around and follow us for more like this every week. See you all soon.