Introduction
Hive Console, as a schema registry, serves the main purpose of preventing breaking changes. This ensures that your GraphQL API stays up-to-date and running smoothly. This allows you to plan ahead and make the necessary modifications to your schema in a timely manner.
A Schema Registry is essential for successfully implementing federated GraphQL APIs, as it ensures consistent schema management and type definitions.
However, it is important to note that determining what constitutes a breaking change can be a complex task. It requires a thorough understanding of your GraphQL API, consumers and real-world traffic patterns. Hive provides a set of tools to help you with this task.
What is a breaking change?
A breaking change in the API ecosystem, is a change that will break the existing consumers of the API, and will cause a disruption.
Since the GraphQL language (called SDL) is fully static and strongly typed, it is possible to determine if a change could be a breaking change.
Here's an example for a change in a GraphQL schema that could be considered a breaking change:
type Query {
posts: [Post]
}
type Post {
id: ID!
title: String!
content: String!
description: String!
}In this example, we removed the description field from the Post type. This is a breaking change
because consumers who depend on the description field in their GraphQL operations (queries,
mutations, subscriptions) will now fail to execute.
This is one example of many supported kinds of possible breaking changes. Hive is using GraphQL-Inspector under the hood.
Breaking changes in practice
In practice, breaking changes are not always breaking. This is because consumers of your GraphQL API might not be using the field that was removed.
For example, let's assume we have the following GraphQL operation:
query Feed_AllPosts {
posts {
id
title
content
# Note: Field "description" is not requested in this query
}
}In this case, the removal of the description field is not a breaking change, because the consumer
of the API is not using this field.
Hive is smart enough to understand this, and will not consider this change as a breaking change. Please, follow the Conditional Breaking Changes guide to enable this feature in your target.
From now on, when a new schema of your GraphQL schema is published to the registry, Hive uses the data collected from your API gateway to identify whether the change in your schema actually affects consumers.
Supported Schema Models
Hive supports the following project types:
- Single Schema: a GraphQL project that has a single GraphQL schema developed as a standalone. This setup works for most frameworks and tools in the GraphQL ecosystem.
- Schema Stitching: a form of remote schema merging allowing developers to merge any GraphQL schema(s), under one or many gateways. You can use either direct Schema Stitching or Hive gateway for this project type.
- GraphQL Federation: a form of remote schema merging developed according to the Federation specification.
If you wish to learn more about how to use Hive with each of these project types, please refer to the following guides:
Actions on schemas
This section covers the actions that can be performed on GraphQL schemas in Hive. Action of schemas can be performed using the Hive CLI or through the Hive Client.
Publish a schema
Publishing a schema is the form of registering a new schema in Hive.
Every schema published to Hive consists of the following data (depends on project type):
| Single Schema | Schema Stitching | GraphQL Federation | |
|---|---|---|---|
| Version Identifier | ✓ | ✓ | ✓ |
| Author | ✓ | ✓ | ✓ |
| Schema SDL | ✓ | ✓ | ✓ |
| Hive Metadata | ✓ | ✓ | ✘ |
| Service Name | ✘ | ✓ | ✓ |
| Service URL | ✘ | ✓ | ✓ |
Here's an overview of what each of these steps means:
- Version Identifier: usually a unique identifier for the schema version. This can a git commit hash, or any other unique identifier that you wish to use.
- Author: the author of the change. This can be a name, an email, or any other identifier. You can use Git author information for this field.
- Schema SDL: the GraphQL schema in SDL format.
- Hive Metadata: Hive metadata is an optional JSON object you can attach to every published schema. You can include any information you wish to include in this JSON object (see Publishing Hive metadata).
- Service Name: the name of the service. This is used for Schema-Stitching and GraphQL
Federation only. A service name is restricted to 64 characters, must start with a letter, and can
only contain alphanumeric,
-, and_characters. - Service URL: the URL of the service. This is used for Schema-Stitching and GraphQL Federation only.
Every schema published to Hive is going through a process of validation, the following steps are performed to ensure a schema is fully valid:
- SDL Parse - the schema is parsed and validated against the GraphQL SDL specification.
- SDL Validate - the schema is validated against the GraphQL specification.
- Metadata validation - if a metadata was published, a JSON schema validation is performed to ensure the metadata is a fully valid JSON object.
- Composition Checks - if the project type is Schema-Stitching or GraphQL Federation, the schema is validated against the composition rules of the project type.
- Schema Changes - A schema
diffis calculated and compared against the previous schema version. If Conditional Breaking Changes is activated, an additional phase of check against collected operations is performed.
For additional reading:
- Publishing a schema using Hive CLI
- Publishing a schema using Hive Client
schema:publishAPI Reference
Check a schema
Checking a GraphQL schema is the form of checking the compatibility of an upcoming schema, compared to the latest published version.
This process of checking a schema needs to be done before publishing a new schema version. This is usually done as part of a CI/CD pipeline, and as part of Pull Request flow.
Every schema checked to Hive is going through a process of validation, the following steps are performed to ensure a schema is valid:
- SDL Parse - the schema is parsed and validated against the GraphQL SDL specification.
- SDL Validate - the schema is validated against the GraphQL specification.
- Composition Checks - if the project type is Schema-Stitching or GraphQL Federation, the schema is validated against the composition rules of the project type.
- Schema Changes - A schema
diffis calculated and compared against the previous schema version. If Conditional Breaking Changes is activated, an additional phase of check against collected operations is performed. If a non-safe change has been introduced in the schema check, it will be rejected by Hive.
For additional reading:
Promote and Rollback Schema Versions
Hive Console supports promoting existing schema versions between targets and rolling back to previously published versions without republishing subgraphs.
Promotions allow teams to safely move a composed supergraph through environments such as staging and production while preserving the exact schema composition.
To promote the latest schema version from one target to another:
hive schema:promote \
--from the-guild/hive/staging \
--to the-guild/hive/productionHive Console creates a new schema version in the destination target using the composed supergraph from the source target and updates the CDN state automatically.
The same command can also be used to roll back a target to a previously published schema version:
hive schema:promote \
--version 9e93a510-6ae7-4361-92d2-bd2370c3b8a8 \
--to the-guild/hive/productionThis is useful for quickly recovering from problematic deployments without removing or republishing subgraphs.
When viewing promoted or rolled-back schema versions in Hive Console, detailed subgraph-level changelogs help identify which subgraphs changed between versions.
For additional reading:
Approve breaking schema changes
Sometimes, you want to allow a breaking change to be published to the registry. This can be done by manually approving a failed schema check on the Hive App.
By approving a schema check. You confirm that you are aware of the breaking changes within the schema check, and want to retain that approval within the context of a pull/merge request or branch lifecycle.
In order to retain the approval of the breaking changes, additional configuration is required. See Checking a schema using Hive CLI.
Fetch a schema
Sometimes it is useful to fetch a schema (SDL or Supergraph) from Hive, for example, to use it in a
local development. This can be done using the schema:fetch command.
Don't confuse this with the high-availability CDN. This command is used to fetch a schema from the API where the CDN always represents the latest valid schema.
Delete a service
This action is only available for Schema-Stitching and GraphQL Federation projects.
Deleting a service is the form of removing a service from the multi-schema project.
For additional reading:
Schema History and Changelog
The Hive Schema History consists of a list of all published schemas, and their respective changes.
In the list of schema versions of changes, you'll be able to see the following information:
- Version Identifier: the version identifier of the schema.
- Author: the author of the change.
- Date: the date of the change.
- Status: the status of the change and the validity of the schema.
- Associated Git Commit: the Git commit associated with the change, when GitHub Integration is enabled for your organization, and a GitHub repository is linked to the Hive project.
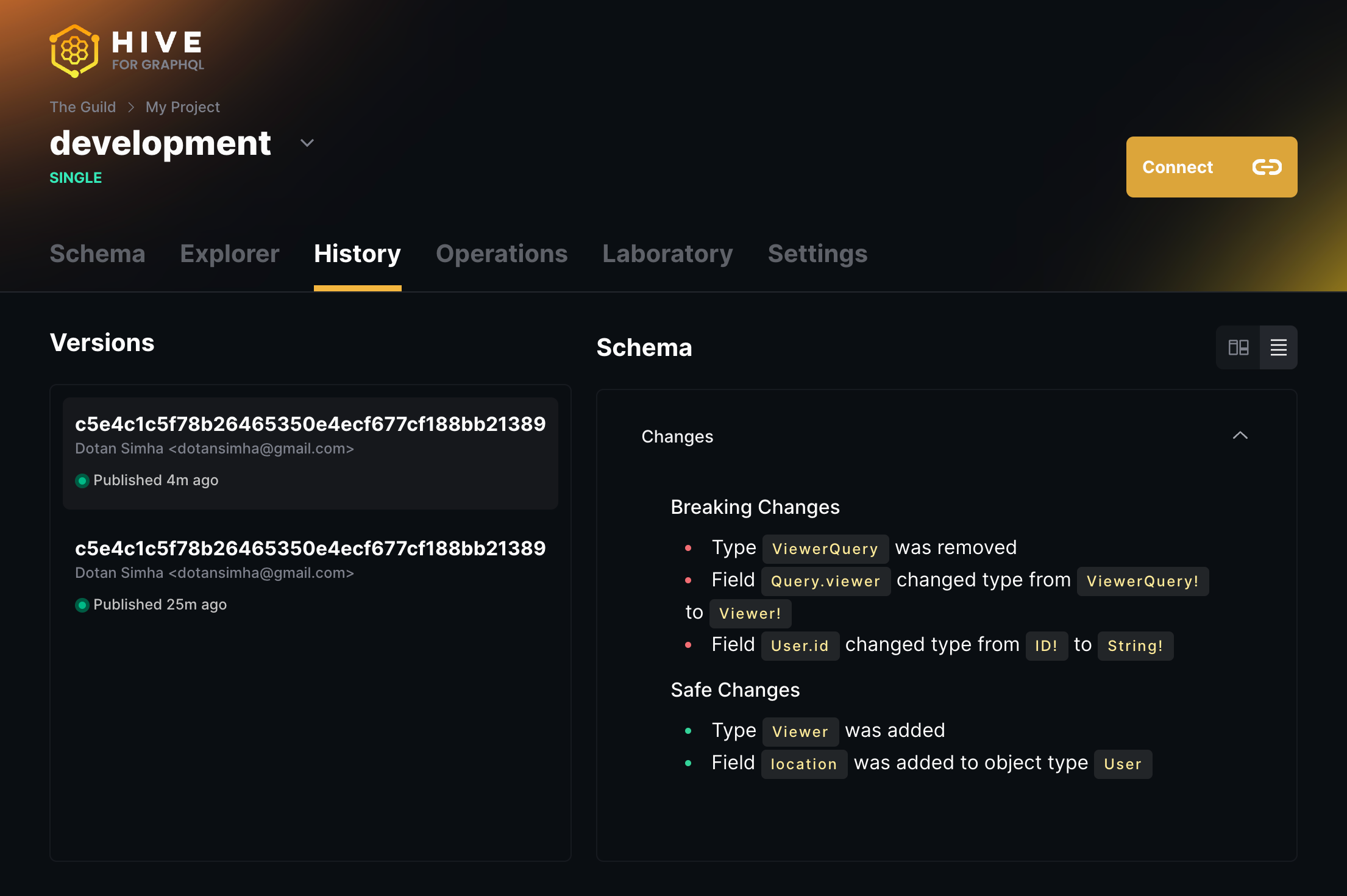
Changelog View
You can inspect a change in your GraphQL schema using the Changelog view. This view provides you an overview of the changes, and their respective impact on your GraphQL schema:
Diff View
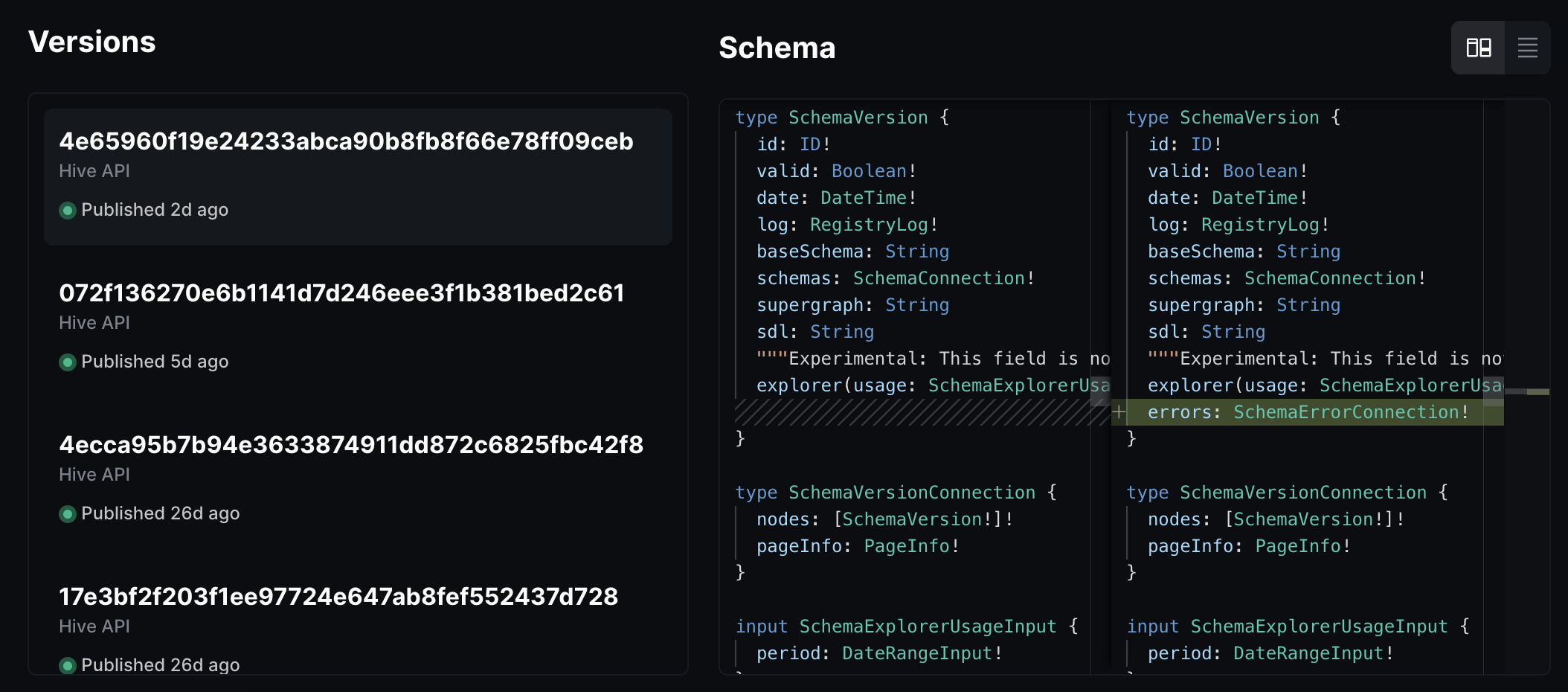
If you wish to have a more technical view of the changes, you can use the diff view: