Get started with a Single Schema / Monorepo
This guide is for projects that do not yet use or require the complexities of GraphQL Federation. A single schema project is great for small teams or smaller projects, where one service hosts the entire API.
Once you’ve created a Hive project of type Single Schema, you can simply push your GraphQL schema to the registry. This guide will guide you through the basics of schema pushing, checking and fetching.
Your GraphQL Schema
If you already have a GraphQL schema from your project, you can use it directly. The Hive CLI can
read GraphQL schemas from .graphql files in your local filesystem.
Using code-first approach to write your GraphQL schema?
Please refer to the Code-First Guide to learn how to use the Hive with code-first approach.
If you don’t have a schema, you can use the following schema in this guide. Copy the contents into a
schema.graphql file and save it to your filesystem:
type Query {
viewer: ViewerQuery!
user(id: ID!): User!
}
type ViewerQuery {
user: User!
role: UserRole!
}
type User {
id: ID!
name: String!
age: Int!
}
enum UserRole {
USER
ADMIN
}Create Access Token
In order to publish our subgraph schemas to the schema registry, we first need to create an access token with the necessary permissions for the Hive CLI.
Within your organization, open the Settings tab and select the Access Token section.
Click Create new access token and enter a name for the access token.

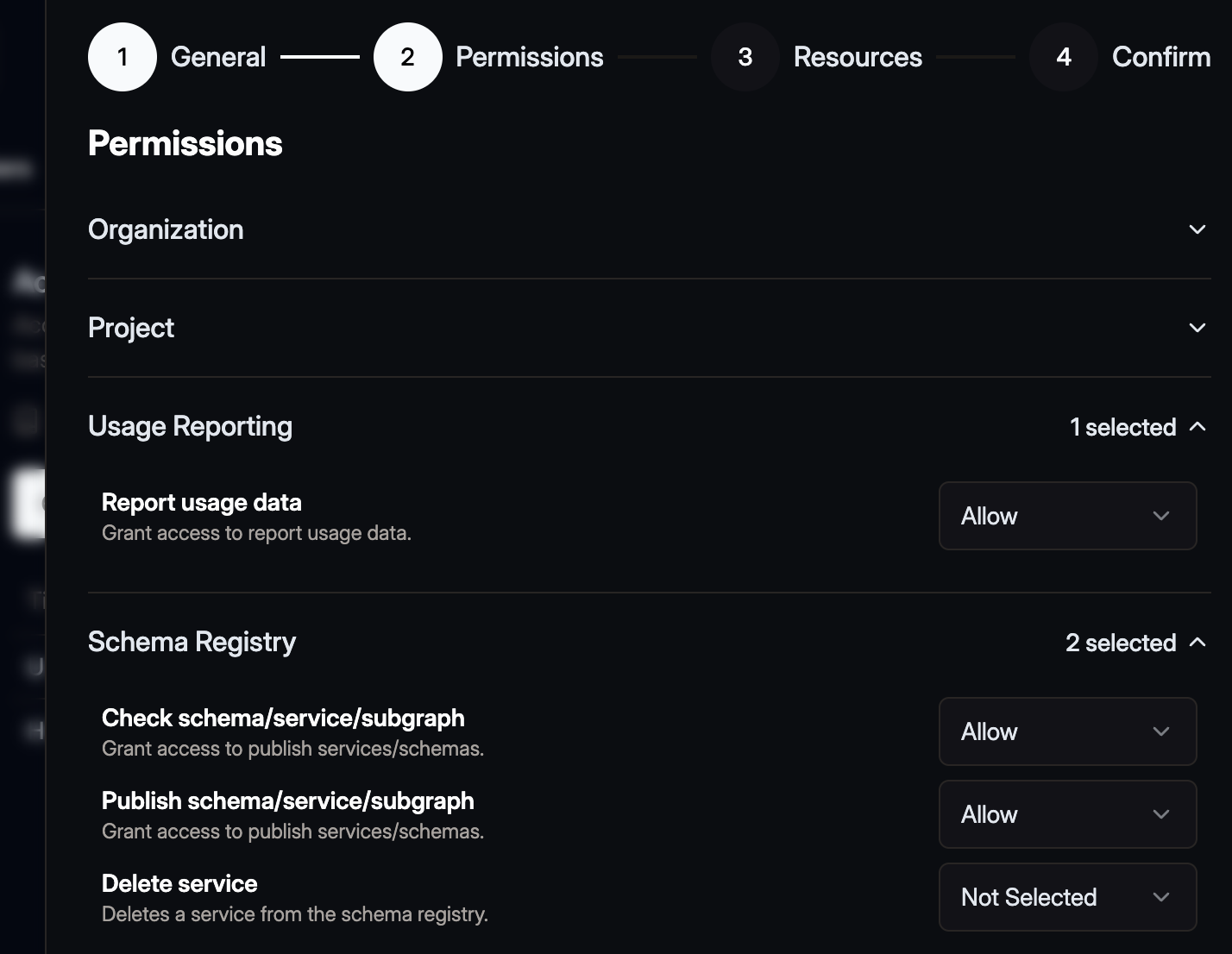
Click Next and select Allowed for Check schema/service subgraph,
Publish schema/service/subgraph, and Report usage data.
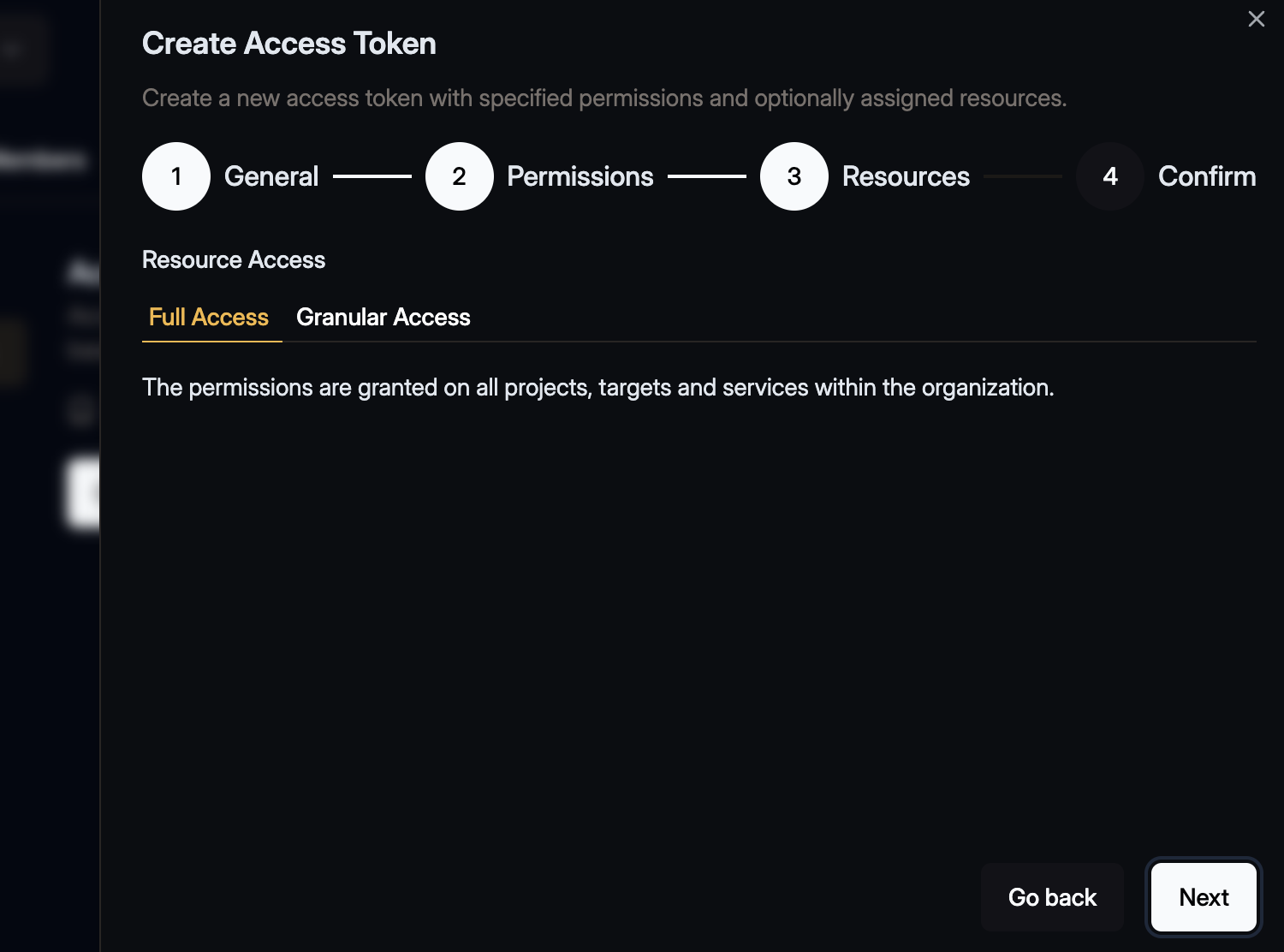
Click Next and in the next step keep the Full Access selection for the resources. For the
purpose of this guide there is no need to further restirct the resources.
One last time click Next and review the access token.
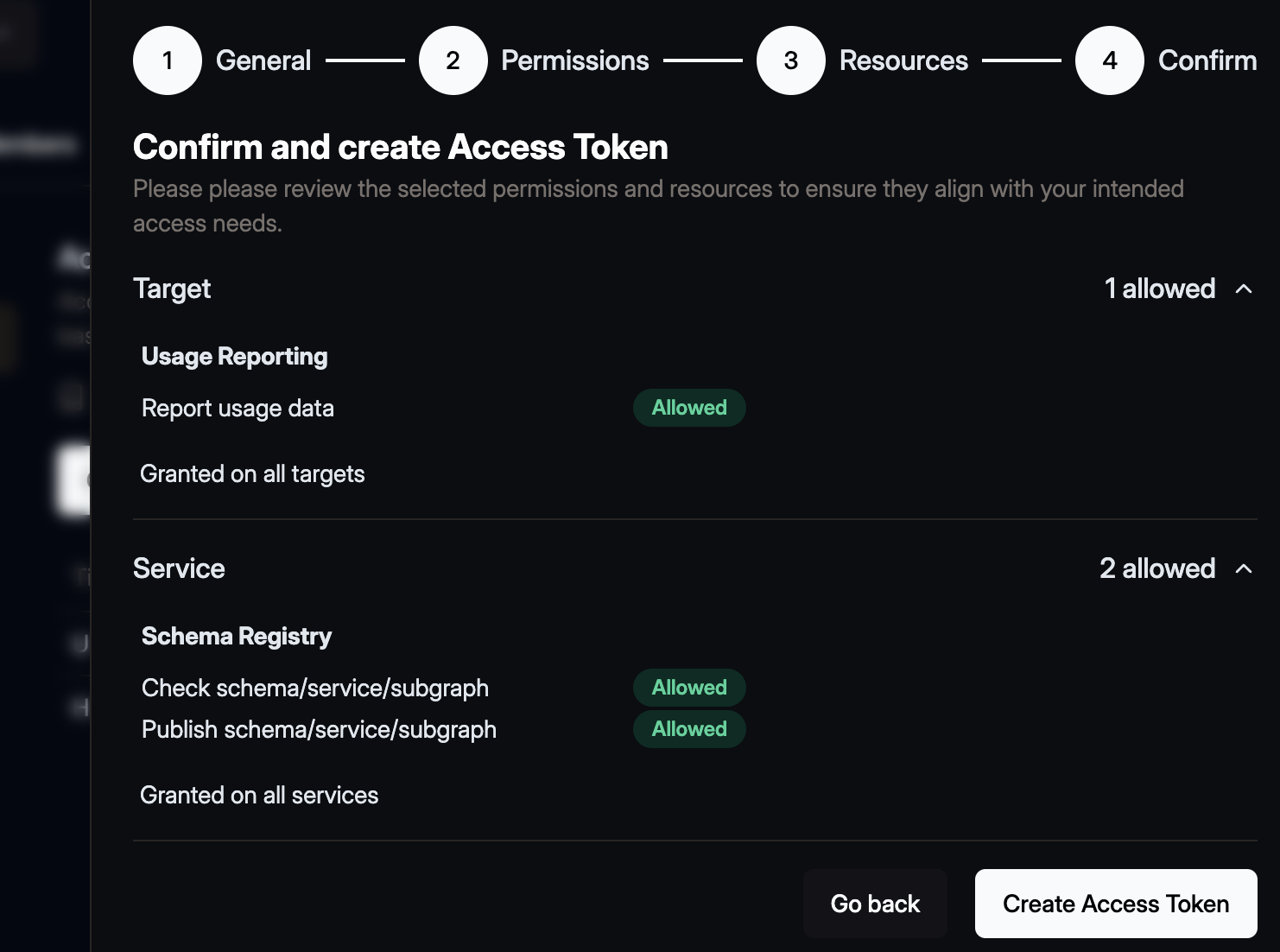
Then click the Create Access Token button. A confirmation dialogue will open that shows the you
generated token.
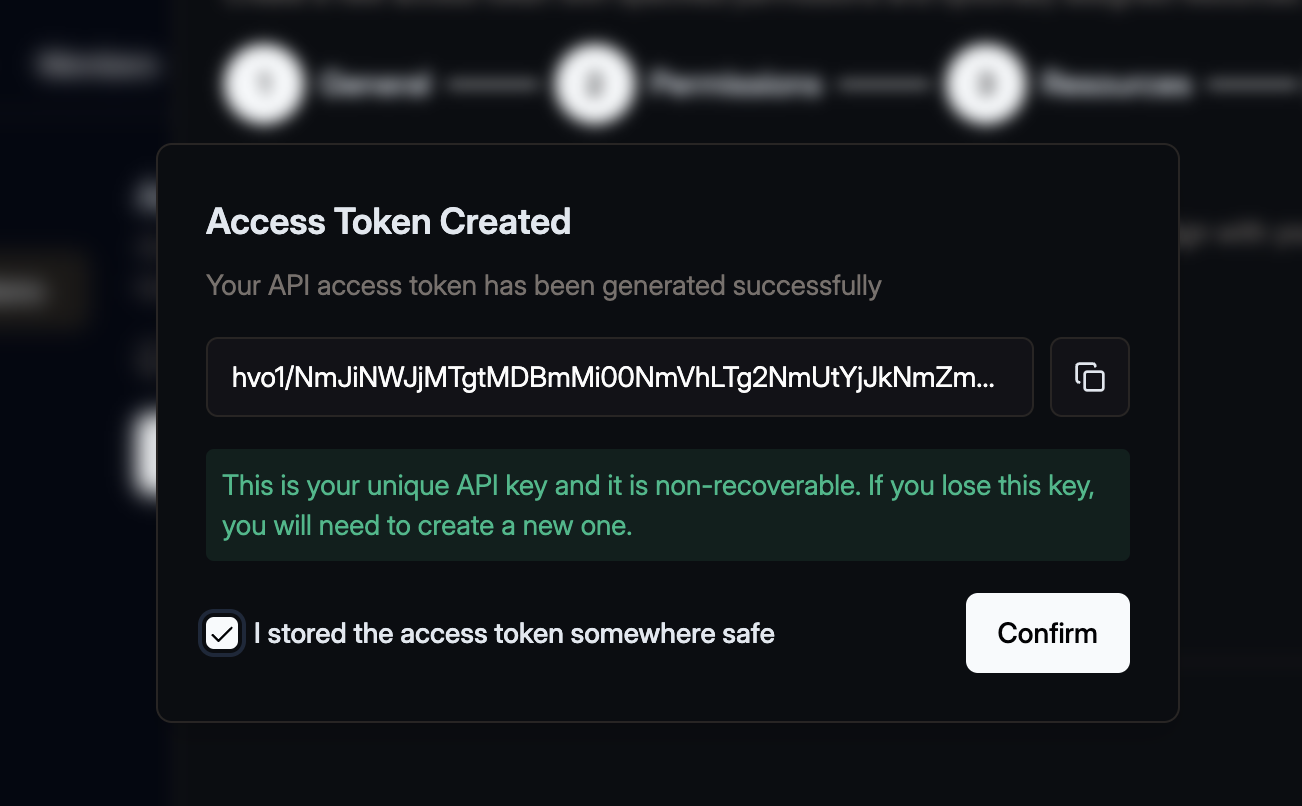
Make sure to copy your token and keep it safe. You won’t be able to see it again.
Publish your first schema
As you may have noticed, Hive has created three targets under your project: development,
staging, and production. This guide will use the development target to explore the features
Hive offers.
For this guide we will use the development target.
Now that you have your access token, you can publish your schema to the registry.
Run the following command in your terminal, to publish your schema.graphql to the registry.
- Replace
<YOUR_ORGANIZATION>with the slug of your organization - Replace
<YOUR_PROJECT>with the slug of your project within the organization - Replace
<YOUR_TOKEN_HERE>with the access token we just created.
hive schema:publish \
--registry.accessToken "<YOUR_TOKEN_HERE>" \
--target "<YOUR_ORGANIZATION>/<YOUR_PROJECT>/development" \
schema.graphqlIf you are running under a NodeJS project, make sure to include the npx, yarn or pnpm prefix
to the command.
If everything goes well, you should see the following output:
✔ Published initial schema.If you’ll get to your target’s page on Hive dashboard, you should see that it was updated with the new schema you just published 🎉
You should also check out the Explorer tab: you can see the schema you just published, and explore the API types, fields, and arguments.
Schema Checks
Hive can perform several checks on your schema before publishing it to the registry. You can use Hive CLI to run these check and find potential breaking changes.
To see how schema checks works, let’s make a small change to our schema.
Open the schema.graphql and make some breaking changes to your GraphQL schema.
First, we’ll start with a non-breaking change - we’ll add a new field to the User type:
type Query {
viewer: ViewerQuery!
user(id: ID!): User!
}
type ViewerQuery {
user: User!
role: UserRole!
}
type User {
id: ID!
name: String!
age: Int!
location: String
}
enum UserRole {
USER
ADMIN
}Now, run the Hive CLI with the schema:check command and your modified schema.graphql file:
hive schema:check \
--registry.accessToken "<YOUR_TOKEN_HERE>" \
--target "<YOUR_ORGANIZATION>/<YOUR_PROJECT>/development" \
schema.graphqlYou should see that Hive successfully detect the change you made, and exists with a 0 exit code,
meaning that the schema is compatible, valid and has no breaking changes:
ℹ Detected 1 change
- Field location was added to object type UserNow, are going to introduce a breaking change. To do that, we’ll change the type named ViewerQuery
to Viewer, and change the type of the id from ID to String:
type Query {
viewer: Viewer!
user(id: ID!): User!
}
# We changed the name of the type from "ViewerQuery" to "Viewer"
type Viewer {
user: User!
role: UserRole!
}
type User {
# We changed an existing field type from "ID" to "String"
id: String!
name: String!
age: Int!
location: String
}
enum UserRole {
USER
ADMIN
}Now, run the Hive CLI with the schema:check command and your modified schema.graphql file:
hive schema:check \
--registry.accessToken "<YOUR_TOKEN_HERE>" \
--target "<YOUR_ORGANIZATION>/<YOUR_PROJECT>/development" \
schema.graphqlNow, you should see that Hive detected a breaking change, and exists with a 1 exit code, meaning
that the schema check failed:
✖ Detected 3 errors
- Breaking Change: Type ViewerQuery was removed
- Breaking Change: Field Query.viewer changed type from ViewerQuery! to Viewer!
- Breaking Change: Field User.id changed type from ID! to String!
ℹ Detected 5 changes
- Type ViewerQuery was removed
- Field Query.viewer changed type from ViewerQuery! to Viewer!
- Field User.id changed type from ID! to String!
- Type Viewer was added
- Field location was added to object type UserEvolve your schema
Now that you have your schema published, you can evolve it over time. You can add new types, fields, and implement new capabilities for your consumers.
Ideally, you should avoid making breaking changes to your GraphQL schema, as they may affect and break consumers who rely on its naming and structure.
However, sometimes breaking changes are necessary to evolve schema. If you decide that a breaking change is valid and necessary, you can still publish a schema with those changes to Hive. Just be aware of the changes and be capable of adjusting your application to them.
To publish your latest schema with breaking changes, use the schema:publish command.
Let’s publish the schema we previously modified:
hive schema:publish \
--registry.accessToken "<YOUR_TOKEN_HERE>" \
--target "<YOUR_ORGANIZATION>/<YOUR_PROJECT>/development" \
schema.graphqlYou should see now that Hive accepted your published schema and updated the registry:
✔ Schema publishedIt’s a good timing to check the History tab of your Hive target. You should see that a new schema is published now, and you can see the changes you made:
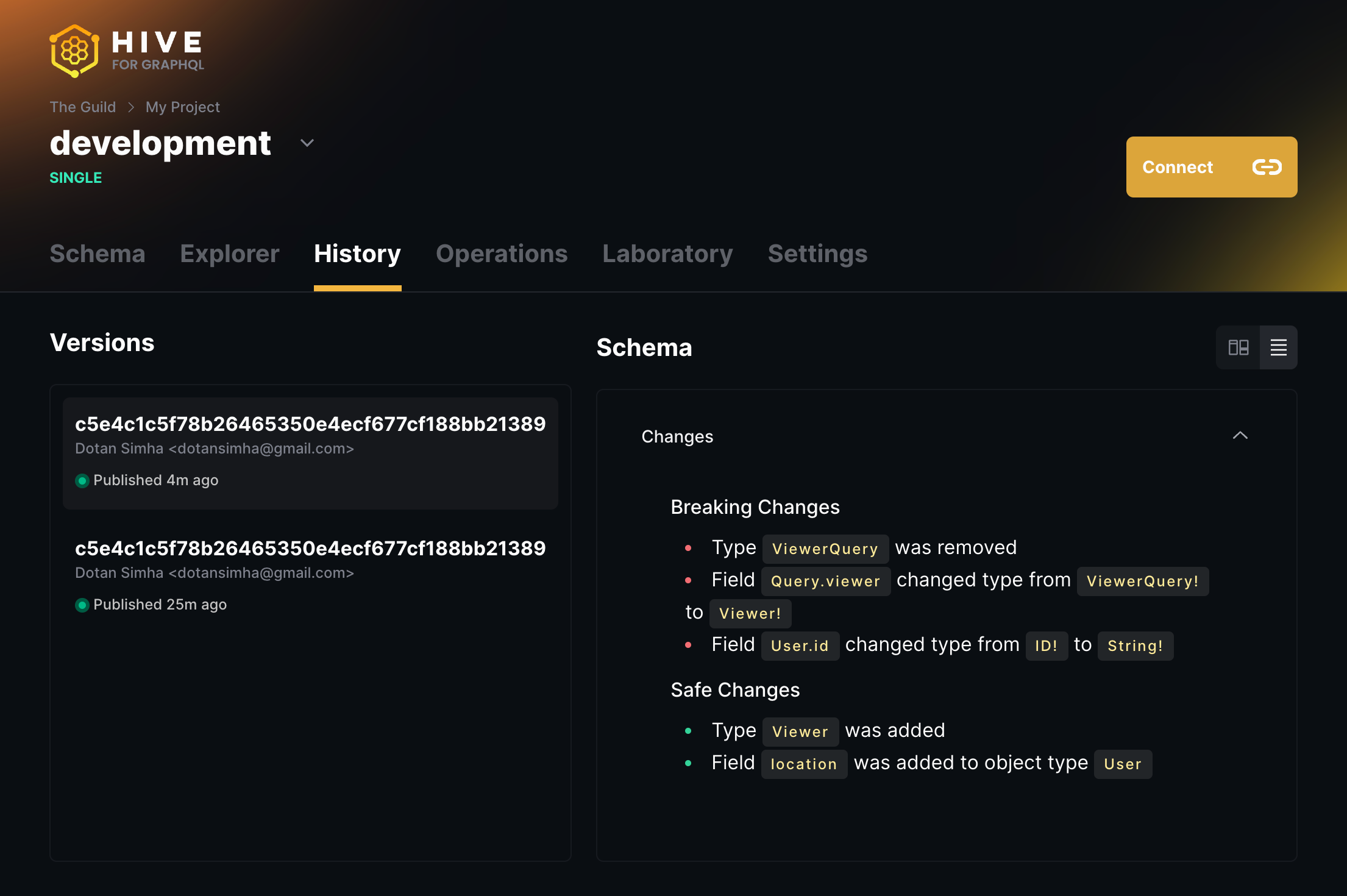
Fetch your schema
Now that your GraphQL schema is stored in the Hive registry, you can access and fetch it through Hive’s CDN (Content Delivery Network).
The Hive Cloud service leverages the CloudFlare Global Network to deliver your GraphQL schema and schema metadata. This means that your schema will be available from the nearest location to your GraphQL gateway, with 100% uptime, regardless of Hive’s status. This ensures that everything required for your GraphQL API is always available, and reduces the risk of depending on Hive as a single point of failure. You can read more about Hive’s CDN here.
To get started with Hive’s CDN access, you’ll need to create a CDN token from your target’s Settings page. You’ll see a separate section for managing and creating CDN tokens, called CDN Access Token.
Click on Create new CDN Token to create a new CDN token. Describe your token with an alias, and click Create. Please store this access token securely. You will not be able to see it again.
Why are Registry and CDN tokens different?
We use a separate, externally managed storage to manage CDN tokens to ensure high availability of your schemas. This approach ensures that your GraphQL schemas are fully secured and highly available. CDN tokens are read-only and can only fetch schemas from the CDN. They do not have permissions to perform any other action on your Hive organization.
To use your access token, go to your target’s page on Hive’s dashboard and click on the Connect to CDN button. You will see a screen with instructions on how to obtain different types of artifacts from the CDN. For this guide, you can pick the GraphQL SDL artifact.
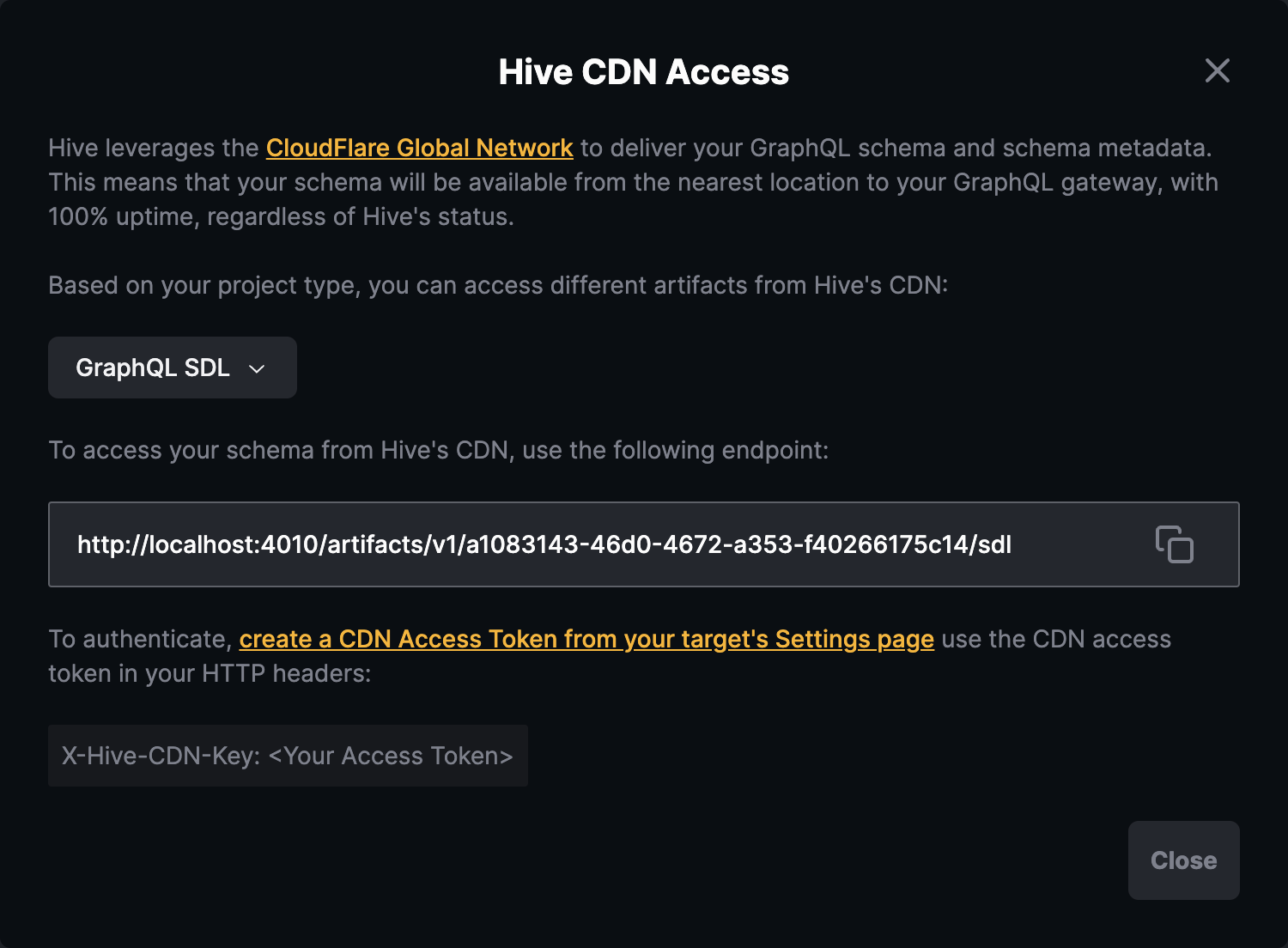
Copy the URL and let’s try to fetch your schema using curl (replace YOUR_HIVE_CDN_TOKEN with
your CDN token, and CDN_ENDPOINT_HERE with the endpoint you copied from Hive’s dashboard):
curl -L -H "X-Hive-CDN-Key: YOUR_HIVE_CDN_TOKEN" CDN_ENDPOINT_HEREYou should see that Hive CDN returns your full GraphQL schema as an output for that command.
Next Steps
Now that you use the basic functionality of Hive as a schema registry, we recommend following other powerful features of Hive: