

Offline GraphQL: The Easy Parts
Your app is perfect. It is fast. It is pretty. It overwhelms the GraphQL server with requests. The UX is really very good. Your CI is perfect. When there's no internet it's unusable. It has 4.9 stars on the App Store. Your app is almost perfect.
Make your app perfect and cache your data on the client. Tear-free.
Reintroducing Brick
Brick runs your data. The easiest way to think of Brick is in terms of pizza, with data as your ingredients.
- You're in a rush, and you just need a slice. You buy one from under the heat lamp. This is memory-cached data.
- You're cooking for a small group and a frozen pie is good enough. This is disk-cached data.
- You want to sit down for a nice meal with the freshest ingredients. This is remote-fetched data.
Brick, can do a lot. But we're here to tell you the good news about fetching the same data from GraphQL, memory, and SQLite.
Let's start with the basics.
Querying in Brick
final repository = OfflineFirstWithGraphqlRepository()
// Queries can be general:
final users = await repository.get<User>();
// Or specific:
final query = Query.where('email', 'user@example.com', limit1: true);
final user = await repository.get<User>(query: query);
// Or associated:
final query = Query.where('customer', Query.where('email', 'user@example.com'));
final user = await repository.get<User>(query: query);That's it. That's how you request data from every pizza source. No switching of memory/remote/disk: it's a single entrypoint.
Runtime Document Generation
While most packages utilize code generation to create GraphQL documents, Brick takes advantage of Dart's strong typing. Your source of truth is your Dart class (which ultimately creates a serialize/deserialize adapter).
This permits the return type to be consistent when being used instead of a new class for every return. By leaving the declaration in Brick, the same source of truth is used to generate and manage SQLite columns.
class User extends OfflineFirstWithGraphqlModel {
final String firstName;
// Request this field as a different name
@Graphql(name: 'last_name')
final String lastName;
// Don't request this field but send it when creating/updating
@Graphql(ignoreFrom: true)
String get name => [firstName, lastName].join(' ');
// Don't request or send this field
@Graphql(ignore: true)
final String? email;
// Customize parsing of GraphQL; useful for differences in language conventions
@Graphql(fromGenerator: 'UserType.values.byName(%DATA_PROPERTY%.toLowerCase())')
final UserType type;
// Document generation can be controller in rare instances where Brick cannot
// detect the subfields of a field type
@Graphql(subfields: {'zipCode': {}})
final Map<String, dynamic> address;
User({
required this.firstName,
required this.lastName,
this.email,
this.type,
});
}
enum UserType { customer, admin }Brick's approach is not without pitfalls. Queries are generally unoptimized - you're always requesting the same data as you would with REST. We found that managing separate-but-very-similar return types was not worth the minimal optimization versus making the same request.
That said, if your requests vary significantly for large models, consider creating two models (e.g.
CustomerLight and a Customer) to use the same structure but with smaller requests.
Some upsert requests (or mutation operations) are much simpler than sending an entire model.
These require variables to be declared, and Brick does not presently support generating
strongly-typed input classes. Instead, a basic, JS-like Map<String, dynamic> can be sent with
Query.
Decipherable Requests
Operations chill alongside business logic. When a GraphQL request is made, Brick will intelligently create the document and use the declared operation from your configuration:
class UserQueryOperationTransformer extends GraphqlQueryOperationTransformer {
GraphqlOperation get get => GraphqlOperation(
document: r'''query Users {
getUsers {}
}'''
);
const UserQueryOperationTransformer(super.query, super.instance);
}
@ConnectOfflineFirstWithGraphql(
graphqlConfig: GraphqlSerializable(
queryOperationTransformer: UserQueryOperationTransformer.new,
)
)
class User extends OfflineFirstWithGraphqlModel {}
// in your state or UI:
final users = await repository.get<User>();These can also be overridden per request but subfields don't need to be declared because they're generated based on the model:
await repository.get<User>(query: Query(
providerArgs: {
'document': r'''
query Users {
getActiveUsers {}
}
'''
}
));Streams!
GraphQL's subscriptions work, youbetcha. Why wait for your data when you could render it immediately?
final subscription = repository.subscribe<User>().listen((users) {});
// In Flutter:
StreamBuilder<List<User>>(
stream: repository.subscribe<User>(),
builder: (_, snap) => Column(children: snap.data.map(Text.new).toList()),
)Even if your GraphQL server doesn't utilize subscriptions, you can still use subscribe. Events
will be triggered every time data is inserted into the local SQLite database.
Always dispose your streams!
Now Make It Offline
Brick follows an optimistic offline-first practice: data is inserted locally before it reaches the server. If the data doesn't exist, Brick requests it from your GraphQL server:

It says REST, but it's the same architecture for GraphQL
Remember, Brick does all of this for you via the single entrypoint. There's no toggling between different data sources in your implementation code.
Retry Queue
If the app is offline when a mutation operation is made, the operation is added to a queue. The queue will reattempt until it receives a successful response from the server. And it will try. And try. And try. We've seen queues retry for 30 days.
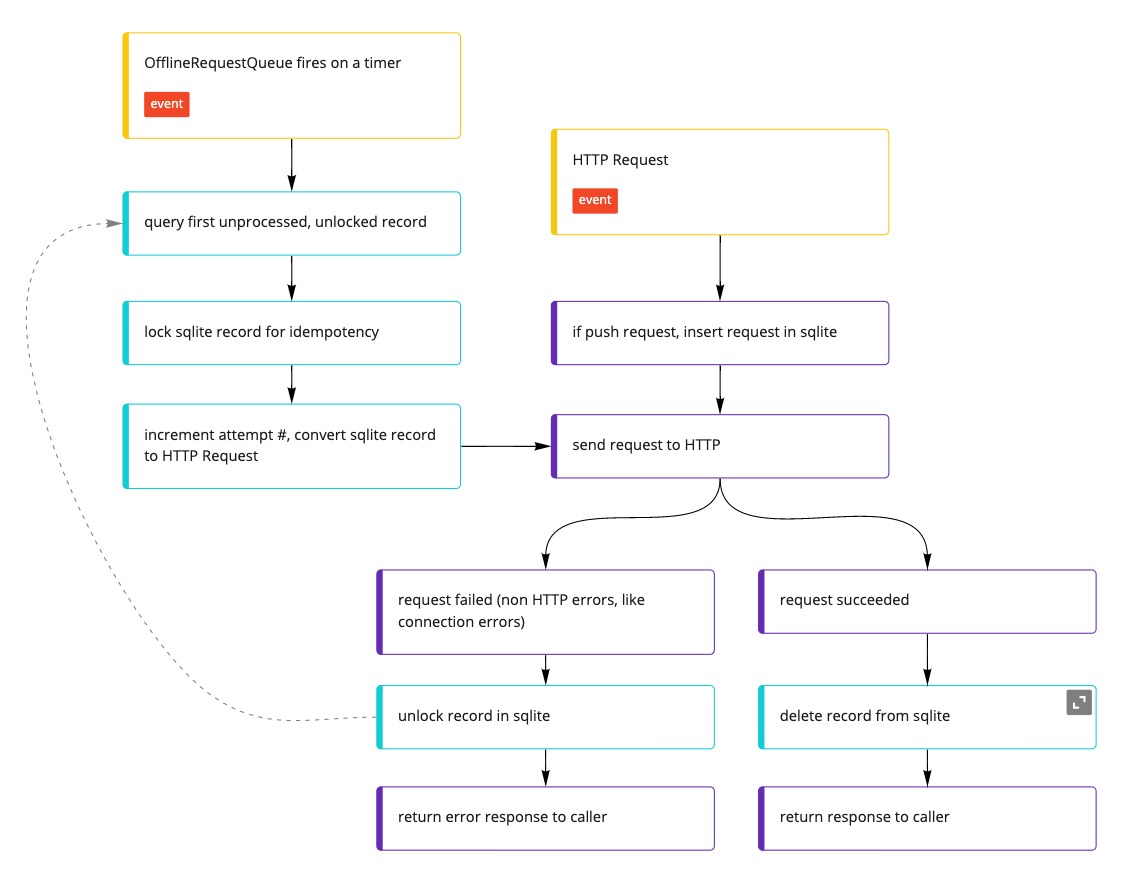
Not your jam? Synchronous execution can be requested (circumventing the queue) by applying the
OfflineFirstUpsertPolicy.awaitRemotepolicy.
You can still use the retry
queue
as an independent link in your gql client. You can also grab requests about
to be
retried
and delete
them
if they're perpetually blocking the queue.
Lost? Inspired? Hungry? Open an issue with us. We'd love to hear from you.