App Deployment (Persisted Operations)
Create an App Deployment
To create an app deployment with the extracted persisted documents, you need to have the Hive CLI installed and authenticated with your Hive target, on which you want to deploy your app.
Note: The GraphQL operations being uploaded must pass validation against the target schema. Otherwise, the app deployment creation will fail.
Once the pre-requisites are met, you can create an app deployment by running the following command.
hive app:create \
--registry.accessToken "<ACCESS_TOKEN>" \
--target "<ORGANIZATION>/<PROJECT>/<TARGET>" \
--name "my-app" \
--version "1.0.0" \
persisted-documents.jsonThe --name parameter is mandatory. The --version parameter is optional - if omitted, a random 7-character alphanumeric version is generated automatically.
Instead of a JSON manifest file, you can also pass a directory or a glob pattern. When a directory or glob is provided, app:create scans for *.graphql files, normalizes each operation, computes a SHA-256 hash per operation, and builds the manifest directly.
# from a directory
hive app:create --name my-app --version 1.0.0 ./src/operations
# from a glob pattern
hive app:create --name my-app --version 1.0.0 "./src/**/*.graphql"
# from an existing manifest file
hive app:create --name my-app --version 1.0.0 persisted-operations.json
# with auto-generated version
hive app:create --name my-app persisted-operations.jsonYou can also pass --publish to publish the app deployment immediately after creation, without needing to run app:publish separately.
hive app:create \
--registry.accessToken "<ACCESS_TOKEN>" \
--target "<ORGANIZATION>/<PROJECT>/<TARGET>" \
--name "my-app" \
--version "1.0.0" \
--publish \
persisted-documents.json| Parameter | Description |
|---|---|
--name | The name of the app deployment. |
--version | The version of the app deployment. Optional - a random version is generated if omitted. |
--publish | Publish the app deployment immediately after creation. Optional. |
<file|directory|glob> | Path to a JSON manifest file, a directory of .graphql files, or a glob pattern matching .graphql files. |
An app deployment is uniquely identified by the combination of the name and version parameters
for each target.
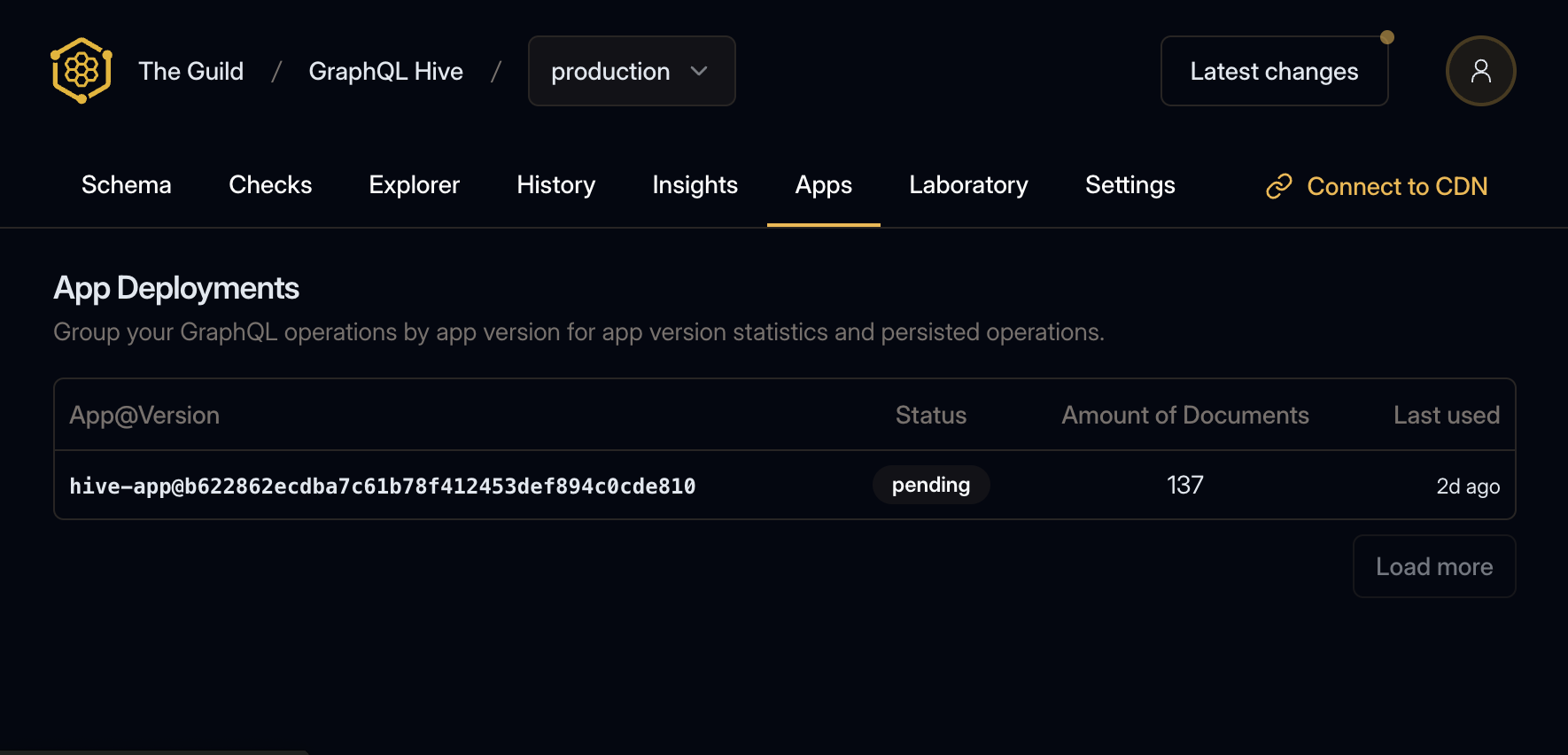
After creating an app deployment, it is in the pending state. That means you can view it on the Hive App UI.
Navigate to the Target page on the Hive Dashboard and click on the Apps tab to see it.
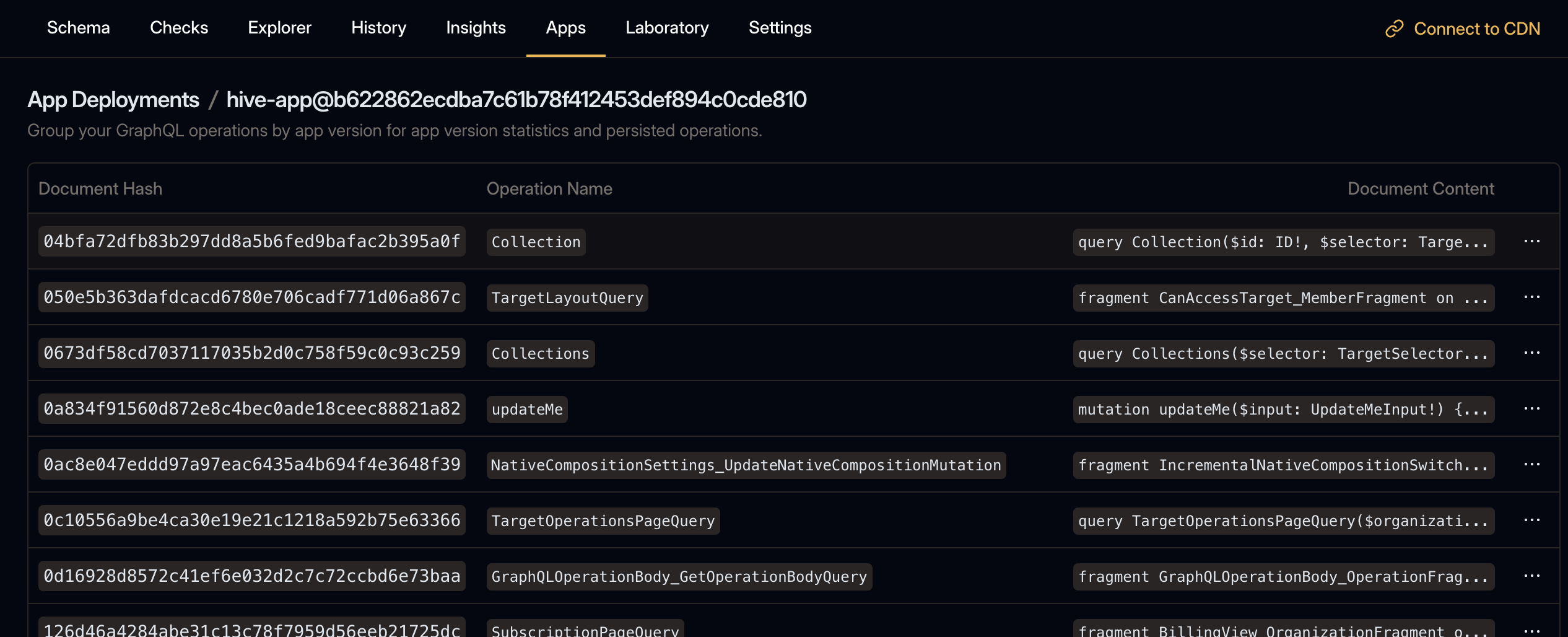
By clicking on the app deployments name, you can navigate to the app deployment details page, where you can see all the GraphQL operations that are uploaded as part of this app deployment.
Further reading:
Publish an App Deployment
A app deployment will be in the pending state until you publish it. By publishing the app deployment, the persisted documents will be available via the Hive CDN and can be used by your Gateway or GraphQL API for serving persisted documents to your app.
To publish an app deployment, you can run the following command. Make sure you utilize the same
--name and --version parameters as you used when creating the app deployment.
hive app:publish \
--registry.accessToken "<ACCESS_TOKEN>" \
--target "<ORGANIZATION>/<PROJECT>/<TARGET>" \
--name "my-app" \
--version "1.0.0"| Parameter | Description |
|---|---|
--name | The name of the app deployment. |
--version | The version of the app deployment. |
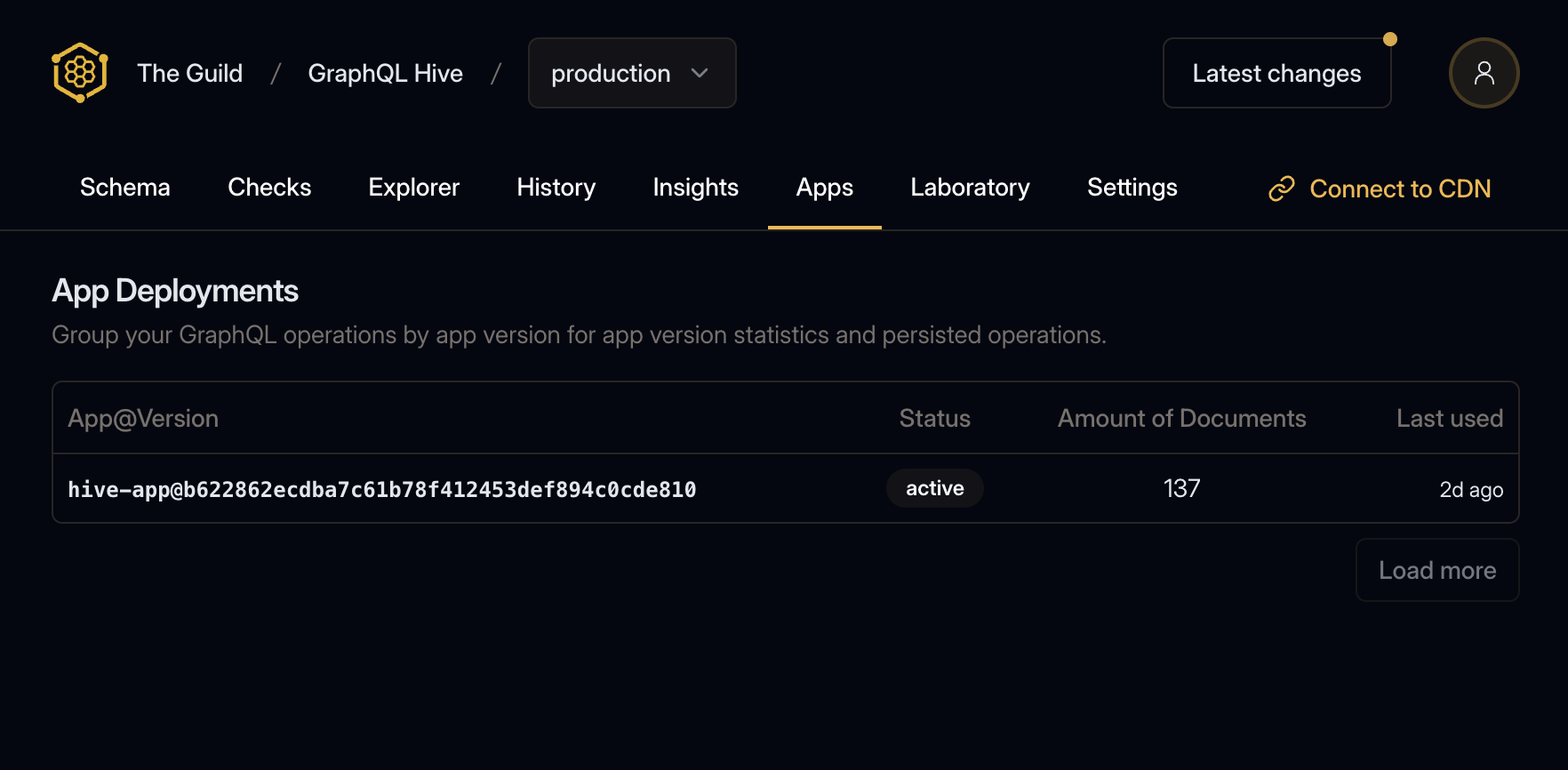
After publishing the app deployment, the persisted documents, the status of the app deployment on the Hive dashboard will change to active.
App deployments are a way to group and publish your GraphQL operations as a single app version to the Hive Registry. This allows you to keep track of your different app versions, their operations usage, and performance.
Making better decisions about:
- Which operations are being used by what app client version (mobile app, web app, etc.)
- Which team or developer is responsible for a specific operation and needs to be contacted for Schema change decisions
Furthermore, it allows you to leverage persisted documents (also knows as trusted documents or persisted queries) on your GraphQL Gateway or server, which provides the following benefits:
- Reduce payload size of your GraphQL requests (reduce client bandwidth usage)
- Secure your GraphQL API by only allowing operations that are known and trusted by your Gateway
Extracting Persisted Documents
We need to extract the persisted documents from within our app. The method for doing this may vary depending on the tools you are using.
The persisted documents must stored in a JSON file, which includes the documents along with their corresponding hashes. This JSON file will be uploaded to the Hive Registry.
{
"d9a00ec0c1ce": "query UsageEstimationQuery($input: UsageEstimationInput!) { __typename usageEstimation(input: $input) { __typename operations } }",
"b8d98e796421": "mutation GenerateStripeLinkMutation($selector: OrganizationSelectorInput!) { __typename generateStripePortalLink(selector: $selector) }"
}These persisted documents define all the possible operations that your app can execute against your GraphQL API.
As long as the app deployment using these persisted documents is active, any change of the GraphQL API that alters the GraphQL schema as used by any of the persisted documents would break that specific app version and therefore be an unsafe/breaking change.
For GraphQL Code Generator, you can configure the client preset to generate the persisted document manifest.
import { type CodegenConfig } from "@graphql-codegen/cli";
const config: CodegenConfig = {
schema: "schema.graphql",
documents: ["src/**/*.tsx"],
generates: {
"./src/gql/": {
preset: "client",
presetConfig: {
persistedDocuments: true,
},
},
},
};After running the Relay Compiler, the file persisted-documents.json will be generated. This file
can be used for creating a new app deployment on Hive.
For more information, please refer to the GraphQL Code Generator documentation.
For Relay Compiler, you can configure the compiler to generate the persisted document manifest.
module.exports = {
src: "./src",
language: "javascript",
schema: "./data/schema.graphql",
excludes: ["**/node_modules/**", "**/__mocks__/**", "**/__generated__/**"],
persistConfig: {
file: "./persisted-documents.json",
},
};After running the Relay Compiler, the file persisted-documents.json will be generated. This file
can be used for creating a new app deployment on Hive.
For more information, please refer to the Relay documentation.
Further reading:
Retire an App Deployment
An app deployment can be retired, which means it is no longer active and the persisted documents are no longer available on the Hive CDN. This is useful when you want to deprecate an old version of your app.
To retire an app deployment, you can run the following command. Make sure you utilize the same
--name and --version parameters as you used when creating the app deployment.
hive app:retire \
--registry.accessToken "<ACCESS_TOKEN>" \
--target "<ORGANIZATION>/<PROJECT>/<TARGET>" \
--name "my-app" \
--version "1.0.0"| Parameter | Description |
|---|---|
--name | The name of the app deployment. |
--version | The version of the app deployment. |
After retiring the app deployment, the status of the app deployment on the Hive dashboard will change to retired.
Further reading:
Finding Stale App Deployments
Hive tracks usage data for your app deployments. Each time a GraphQL request uses a persisted document from an app deployment, Hive records when it was last used. This data helps you identify app deployments that are candidates for retirement.
Usage Tracking
When your GraphQL server or gateway reports usage to Hive, the lastUsed timestamp for the
corresponding app deployment is updated. You can see this information in the Hive dashboard or query
it via the GraphQL API.
Querying Stale Deployments via GraphQL API
You can use the activeAppDeployments query to find app deployments that match specific criteria.
The date filters (lastUsedBefore, neverUsedAndCreatedBefore) use OR semantics. deployments
matching either date condition are returned. The name filter uses AND semantics to narrow down
results.
query FindStaleDeployments($target: TargetReferenceInput!) {
target(reference: $target) {
activeAppDeployments(
filter: {
# Optional: filter by app name (case-insensitive partial match)
name: "my-app"
# Deployments last used more than 30 days ago
lastUsedBefore: "2024-11-01T00:00:00Z"
# OR deployments that have never been used and are older than 30 days
neverUsedAndCreatedBefore: "2024-11-01T00:00:00Z"
}
) {
edges {
node {
name
version
createdAt
lastUsed
}
}
}
}
}| Filter Parameter | Description |
|---|---|
name | Filter by app deployment name (case-insensitive partial match). Uses AND semantics. |
lastUsedBefore | Return deployments that were last used before this timestamp. Uses OR with other date filter. |
neverUsedAndCreatedBefore | Return deployments never used and created before this timestamp. Uses OR with other date filter. |
Retirement Workflow
A typical workflow for retiring stale deployments:
- Query stale deployments using the
activeAppDeploymentsquery with appropriate filters - Review the results to ensure you're not retiring deployments still in use
- Retire deployments using the
app:retireCLI command or GraphQL mutation
Automated Cleanup
For teams with many app deployments (e.g., one per PR or branch), you can automate cleanup by combining the GraphQL API with the Hive CLI.
Example script pattern:
# Query stale deployments via GraphQL API
# Parse the response to get app names and versions
# Retire each deployment using the CLI:
hive app:retire \
--registry.accessToken "<ACCESS_TOKEN>" \
--target "<ORGANIZATION>/<PROJECT>/<TARGET>" \
--name "<app-name>" \
--version "<app-version>"Always review deployments before retiring them programmatically. Consider protecting your latest production deployment to avoid accidentally retiring active versions.
Schema Checks and Affected App Deployments
When you run a schema check that detects breaking changes, Hive automatically identifies which active app deployments would be affected by those changes. This helps you understand the real-world impact of schema changes before deploying them.
How It Works
During a schema check, Hive analyzes the breaking changes and matches them against the persisted
documents in your active app deployments. Hive identifies all app deployments that have operations
using any of the affected schema coordinates (e.g., fields like Query.hello that are being
removed).
For each affected app deployment, you'll see:
- The deployment name and version
- Which specific operations within that deployment use the affected schema coordinates
This information is displayed alongside the breaking changes in the schema check results, helping you understand the collective impact across all your active app deployments.
Example
If you have a breaking change that removes the Query.users field, and you have an active app
deployment mobile-app@2.1.0 with operations that query Query.users, the schema check will show:
- The breaking change: "Field 'users' was removed from object type 'Query'"
- Affected app deployment:
mobile-appversion2.1.0 - Affected operations: The specific operation names and hashes that use this field
Benefits
- Impact assessment: Understand which client applications would break before deploying schema changes
- Coordination: Know which teams need to update their apps before a breaking change can be safely deployed
- Risk mitigation: Make informed decisions about whether to proceed with breaking changes or find alternative approaches
Only active app deployments (published and not retired) are checked for affected operations. Pending and retired deployments are not included in this analysis.
Persisted Documents on GraphQL Server and Gateway
Persisted documents can be used on your GraphQL server or Gateway to reduce the payload size of your GraphQL requests and secure your GraphQL API by only allowing operations that are known and trusted by your Gateway.
Hive serves as the source of truth for the allowed persisted documents and provides a CDN for fetching these documents as they are requested.
For Hive Gateway you can use the Hive configuration for resolving persisted documents. Adjust your
gateway.config.ts file as follows.
import { defineConfig } from "@graphql-hive/gateway";
export const gatewayConfig = defineConfig({
persistedDocuments: {
type: "hive",
// The endpoint of Hive's CDN
endpoint: [
"https://cdn.graphql-hive.com/artifacts/v1/<target_id>",
"https://cdn-mirror.graphql-hive.com/artifacts/v1/<target_id>",
],
// The CDN token provided by Hive Registry
key: "<cdn access token>",
},
});For further information, please refer to the Hive Gateway documentation for persisted documents.
For GraphQL Yoga you can use the Hive CDN for resolving persisted documents via the Hive SDK.
npm i -D @graphql-hive/yogaimport { createYoga } from "graphql-hive";
import { useHive } from "@graphql-hive/yoga";
import schema from "./schema.js";
const yoga = createYoga({
schema,
plugins: [
useHive({
enabled: false,
persistedDocuments: {
cdn: {
// replace <target_id> and <cdn_access_token> with your values
endpoint: [
"https://cdn.graphql-hive.com/artifacts/v1/<target_id>",
"https://cdn-mirror.graphql-hive.com/artifacts/v1/<target_id>",
],
accessToken: "<cdn_access_token>",
},
},
}),
],
});For further configuration options, please refer to the Hive Client API reference.
Layer 2 Cache (Optional)
For serverless environments or multi-instance deployments, you can add a Layer 2 (L2) cache between the in-memory cache and the CDN. This is useful when in-memory cache is lost between invocations or to share cached documents across server instances.
import { createYoga } from "graphql-hive";
import { createClient } from "redis";
import { useHive } from "@graphql-hive/yoga";
import schema from "./schema.js";
const redis = createClient({ url: "redis://localhost:6379" });
await redis.connect();
const yoga = createYoga({
schema,
plugins: [
useHive({
enabled: false,
persistedDocuments: {
cdn: {
endpoint: "https://cdn.graphql-hive.com/artifacts/v1/<target_id>",
accessToken: "<cdn_access_token>",
},
layer2Cache: {
cache: {
get: (key) => redis.get(`hive:pd:${key}`),
set: (key, value, opts) =>
redis.set(
`hive:pd:${key}`,
value,
opts?.ttl ? { EX: opts.ttl } : {},
),
},
ttlSeconds: 3600, // 1 hour for found documents
notFoundTtlSeconds: 60, // 1 minute for not-found (negative caching)
},
},
}),
],
});The lookup flow is: L1 (memory) -> L2 (Redis/external) -> CDN
| Option | Description |
|---|---|
cache.get | Async function to get a value from the cache. Returns null for cache miss. |
cache.set | Async function to set a value in the cache. Receives an optional ttl option. |
ttlSeconds | TTL in seconds for successfully found documents. |
notFoundTtlSeconds | TTL in seconds for not-found documents (negative caching). Set to 0 to disable. Default: 60 |
waitUntil | Optional function for serverless environments to ensure cache writes complete. |
For Apollo Server you can use the Hive CDN for resolving persisted documents via the Hive SDK.
npm i -D @graphql-hive/apolloimport { ApolloServer } from "@apollo/server";
import { useHive } from "@graphql-hive/apollo";
import schema from "./schema.js";
const server = new ApolloServer({
schema,
plugins: [
useHive({
persistedDocuments: {
cdn: {
// replace <target_id> and <cdn_access_token> with your values
endpoint: "https://cdn.graphql-hive.com/artifacts/v1/<target_id>",
accessToken: "<cdn_access_token>",
},
},
}),
],
});For further configuration options, please refer to the Hive Client API reference.
Layer 2 Cache (Optional)
Apollo Server automatically uses the server's cache backend for L2 caching if available. You can also configure a custom L2 cache:
import { createClient } from "redis";
import { ApolloServer } from "@apollo/server";
import { useHive } from "@graphql-hive/apollo";
import schema from "./schema.js";
const redis = createClient({ url: "redis://localhost:6379" });
await redis.connect();
const server = new ApolloServer({
schema,
plugins: [
useHive({
persistedDocuments: {
cdn: {
endpoint: "https://cdn.graphql-hive.com/artifacts/v1/<target_id>",
accessToken: "<cdn_access_token>",
},
layer2Cache: {
cache: {
get: (key) => redis.get(`hive:pd:${key}`),
set: (key, value, opts) =>
redis.set(
`hive:pd:${key}`,
value,
opts?.ttl ? { EX: opts.ttl } : {},
),
},
ttlSeconds: 3600,
notFoundTtlSeconds: 60,
},
},
}),
],
});To use App Deployments with Apollo-Router, you can use the Hive CDN for resolving persisted documents.
Use the Apollo Router custom build for Hive as an alternative to the official Apollo Router.
Enable the Persisted Document plugin by adding the following to your router.yaml configuration.
# ... the rest of your configuration
plugins:
hive.usage:
target: "<ORGANIZATION>/<PROJECT>/<TARGET>"
hive.persisted_documents:
enabled: trueThe plugin uses the HIVE_CDN_ENDPOINT and HIVE_CDN_KEY environment variables to resolve the
persisted documents IDs.
For additional information and configuration options, please refer to the Apollo-Router integration page.
Any published app deployment is available via the Hive CDN. You can fetch a the persisted documents by doing a HTTP GET request.
GET https://cdn.graphql-hive.com/artifacts/v1/<target_id>/apps/<app_name>/<app_version>/<document_hash>| Parameter | Description |
|---|---|
target_id | The target ID of the Hive target where the app deployment is published. |
app_name | The name of the app deployment. |
app_version | The version of the app deployment. |
document_hash | The hash of the persisted document. |
Example curl request:
curl \
-L \
-H 'X-Hive-CDN-Key: CDN_ACCESS_TOKEN' \
https://cdn.graphql-hive.com/artifacts/v1/<target_id>/apps/<app_name>/<app_version>/<document_hash>Expected responses:
| Response Status | Description |
|---|---|
| 200 | The persisted document was found and is returned in the response body. |
| 404 | The persisted document does not exist. |
| 401 | The request is unauthorized. A valid CDN access token must be provided. |
Sending Persisted Document Requests from your App
Once you have the persisted documents available on your GraphQL server or Gateway, you can send a GraphQL request with the persisted document ID following the GraphQL over HTTP specification.
POST /graphql
Content-Type: application/json
{
"documentId": "<app_name>~<app_version>~<document_hash>",
}| Parameter | Description |
|---|---|
app_name | The name of the app deployment. |
app_version | The version of the app deployment. |
document_hash | The hash of the persisted document. |
Example curl request:
curl \
-X POST \
-H 'Content-Type: application/json' \
-d '{"documentId": "<app_name>~<app_version>~<document_hash>"}' \
http://localhost:4000/graphqlThe code demonstrates how to send a persisted document request using Apollo Client. Make sure to replace the placeholders with your actual values.
import { ApolloClient, HttpLink, InMemoryCache } from "@apollo/client";
import { createPersistedQueryLink } from "@apollo/client/link/persisted-queries";
// replace <app_name>, <app_version>, and with your values
const appVersionPrefix = "<app_name>~<app_version>~";
const persistedQueriesLink = createPersistedQueryLink({
generateHash(document) {
// GraphQL Code Generator Client Preset generates
// the persisted document ID within the document node.
// For other implementations return the hash prefixed with the app version.
if (document?.["__metadata__"]?.["hash"]) {
throw Error("Hash not available for document");
}
return appVersionPrefix + document["__metadata__"]["hash"];
},
});
const httpLink = new HttpLink({
uri: "/graphql",
fetch(url, init) {
const parsedBody = JSON.parse(init!.body as string);
return fetch(url, {
...init,
body: JSON.stringify({
variables: parsedBody.variables,
documentId: parsedBody.extensions.persistedQuery.sha256Hash,
extensions: { ...parsedBody.extensions, persistedQuery: undefined },
}),
});
},
});
const client = new ApolloClient({
cache: new InMemoryCache(),
link: persistedQueriesLink.concat(httpLink),
});| Parameter | Description |
|---|---|
<app_name> | The name of the app deployment. |
<app_version> | The version of the app deployment. |
The code demonstrates how to send a persisted document request using Urql. Make sure to replace the placeholders with your actual values.
import { createClient, fetchExchange, mapExchange } from "urql";
// replace <app_name>, <app_version>, and with your values
const appVersionPrefix = "<app_name>~<app_version>~";
const urqlClient = createClient({
url: "/graphql",
exchanges: [
mapExchange({
onOperation(op) {
if (op.query?.["__metadata__"]?.["hash"]) {
throw Error("Hash not available for document");
}
return {
...op,
query: {
documentId:
// GraphQL Code Generator Client Preset generates
// the persisted document ID within the document node.
// For other implementations return the hash prefixed with the app version.
appVersionPrefix + op.query["__meta__"]["hash"],
definitions: [],
},
};
},
}),
fetchExchange,
],
});| Parameter | Description |
|---|---|
<app_name> | The name of the app deployment. |
<app_version> | The version of the app deployment. |
Update your Relay environment configuration to send persisted document requests instead of the document.
// replace <app_name>, <app_version>, and with your values
const appVersionPrefix = "<app_name>~<app_version>~";
function fetchQuery(operation, variables) {
if (!operation.id) {
throw new Error("No persisted document hash provided.");
}
return fetch("/graphql", {
method: "POST",
headers: {
"content-type": "application/json",
},
body: JSON.stringify({
documentId: appVersionPrefix + operation.id,
variables,
}),
}).then((response) => response.json());
}| Parameter | Description |
|---|---|
<app_name> | The name of the app deployment. |
<app_version> | The version of the app deployment. |
Continuous Deployment (CD) Integration
We recommend integrating the app deployment creation and publishing into your CD pipeline for automating the creating and publishing of app deployments.
Usually the following steps are performed.
Since the application will be configured to send requests with the persisted document ID, we need to ensure that these documents are available on the Hive CDN before deploying the application.
Extracting the persisted documents usually happens during the build step of your application. E.g. if you are using GraphQL Code Generator with the client preset or Relay, the persisted document JSON mapping is generated as an artifact.
In your CLI pipeline, you can then use the Hive CLI (or Hive CLI docker container) to create and publish the app deployment.
After that, you can deploy your application with confidence.
Tools like GitHub Actions, Pulumni, or Terraform can be used to model this flow. We use it ourselves for deploying the GraphQL Hive Dashboard using Pulumni.