
Today we are happy to announce that we are open sourcing a framework we've been using for the past couple of months in production — GraphQL Modules!
Yet another framework? well, kind of GraphQL Modules is a set of extra libraries, structures and guidelines around the amazing Apollo Server 2.0.
You can and should use them as completely separate packages, each one is good for different use cases, but all together they represent our current philosophy of building large scale GraphQL servers.
We would love to get feedback from the Apollo team and if they wish to use those ideas and integrate them into Apollo Server we would love to contribute. That's why we've developed it as a set of independent tools under a single monorepo.
The basic concept behind GraphQL Modules is to separate your GraphQL server into smaller, reusable, feature based parts.
A basic and initial implementation of a GraphQL server usually includes:
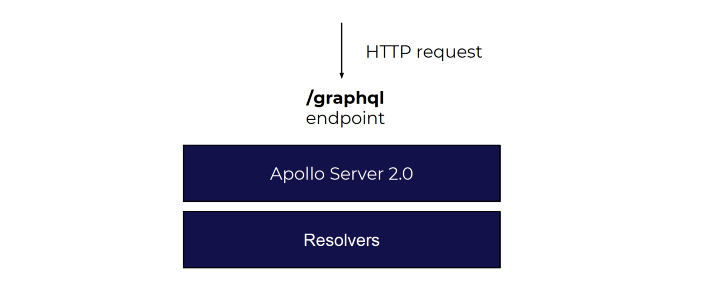
A more advanced implementation will usually use a context to inject things like data models, data sources, fetchers, etc., like Apollo Server 2.0 provides us with:
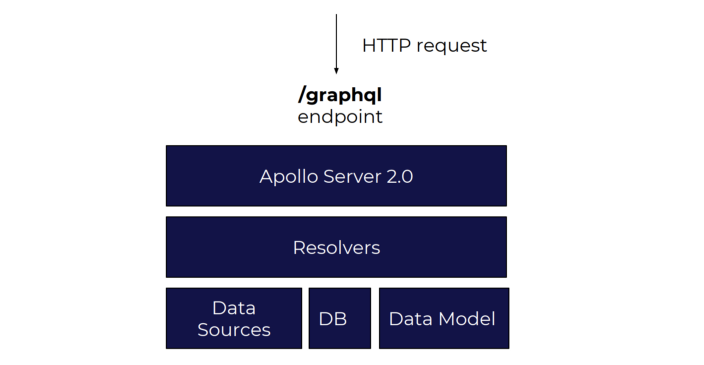
Usually, for simple use cases, the example above will do.
But as applications grow, their code and schematic relationships becomes bigger and more complex, which can make schema maintenance a hard and agonizing thing to work with.
Some of the more old school, MVC frameworks adds few more layers after the resolvers layer, but most of them just implement separation based technical layers: controllers, models, etc.
We argue that there is a better approach of writing your GraphQL Schema and implementation.
We believe you should separate your GraphQL schema by modules, or features, and includes anything related to a specific part of the app under a “module” — which is just a simple directory. Each one of the GraphQL Modules libraries would help you in the gradual process of doing that.
The modules are being defined by their GraphQL schema — so we've taken the “GraphQL First” approach lead by Apollo and combined it together with classic modularization tooling to create new ways of writing GraphQL servers!

The GraphQL Modules toolset has tools to help with:
- Schema Separation — declare your GraphQL schema in smaller pieces, which you can later move and reuse.
- Tools designed to create independent modules — each module is completely independent and testable, and can be shared with other applications or even open sourced if needed
- Resolvers Composition — with GraphQL Modules you can write your resolver as you wish, and let
the app that hosts the module to wrap the resolvers and extend them. It's implemented with a basic
middleware API, but with more flexibility. That means that you can, for example, implement your
entire module without knowing about the app authentication process, and assume that
currentUserwill be injected for you by the app. - A clear, gradual path from a very simple and fast, single-file modules, to scalable multi-file, multi-teams, multi-repo, multi-server modules.
- A scalable structure for your GraphQL servers — managing multiple teams and features, multiple microservices and servers and more advanced tools, which you can choose to include when your schema gets into massive scale:
- Communication Bridge — We also let you send custom messages with payload between modules — that means you can even run modules in different microservices and easily interact between them.
- Dependency Injection — Implement your resolvers, and later, only when you see fit, improve their implementation by gradually introducing dependency injection. It also includes richer toolset around testing and mocking.
A Basic Example
In the following example, you can see a basic implementation for GraphQL Modules server, with 2
modules: User and Chat. Each module declares only the part that is relevant to it, and extends
previously declared GraphQL types.
So when User module is loaded, the type User is created, and when Chat module is loaded, the
type User being extended with more fields.
import { GraphQLModule } from "@graphql-modules/core";
import { ChatModule } from "./chat-module";
import { UserModule } from "./user-module";
export const appModule = new GraphQLModule({
imports: [UserModule, ChatModule],
});import { GraphQLModule } from '@graphql-modules/core';
import gql from 'graphql-tag';
export const ChatModule = new GraphQLModule({
typeDefs: gql`
# Query declared again, adding only the part of the schema that relevant
type Query {
myChats: [Chat]
}
# User declared again- extends any other `User` type that loaded into the appModule
type User {
chats: [Chat]
}
type Chat {
id: ID!
users: [User]
messages: [ChatMessage]
}
type ChatMessage {
id: ID!
content: String!
user: User!
}
`,
resolvers: {
Query: {
myChats: (root, args, { getChats, currentUser }) => getChats(currentUser),
},
User: {
// This module implements only the part of `User` it adds
chats: (user, args, { getChats }) => getChats(user),
},
},
});import { ApolloServer } from "apollo-server";
import { appModule } from "./modules/app";
const { schema, context } = appModule;
const server = new ApolloServer({
schema,
context,
introspection: true,
});
server.listen();import { GraphQLModule } from '@graphql-modules/core';
import gql from 'graphql-tag';
export const UserModule = new GraphQLModule({
typeDefs: gql`
type Query {
me: User
}
# This is a basic User, with just the basics of a user object
type User {
id: ID!
username: String!
email: String!
}
`,
resolvers: {
Query: {
me: (root, args, { currentUser ) => currentUser,
},
User: {
id: user => user._id,
username: user => user.username,
email: user => user.email.address,
},
},
});You can and should adopt GraphQL Modules part by part, and you can try it now with your existing GraphQL server.
What does a “module” contain?
- Schema (types declaration) — each module can define its own Schema, and can extend other schema types (without explicitly providing them).
- Thin resolvers implementation — each module can implement its own resolvers, resulting in thin resolvers instead of giant files.
- Providers — each module can have its own Providers, which are just classes/values/functions that you can use from your resolvers. Modules can load and use providers from other modules.
- Configuration — each module can declare a strongly-typed config object, which the consuming app can provide it with.
- Dependencies — modules can be dependent on other modules (by its name or its
GraphQLModuleinstance, so you can easily create an ambiguous dependency that later could be changed).
GraphQL Modules Libraries
GraphQL Modules is built as a toolkit, with the following tools, which you should individually and gradually adopt:
@raphql-modules/epoxy
- That will probably be the first tool you want to introduce into your server. The first step into organizing your server in a feature based structure
- Epoxy is a small util that manages the schema merging. it allow you to merge everything in your schema, starting from types to enums, unions, directives and so on.
- This is an important feature of GraphQL Modules — you can use it to separate your GraphQL types to smaller pieces and later on combine them into a single type.
- We took the inspiration from merge-graphql-schemas, and added some features on top of it to allow custom merging rules to make it easier to separate your schema.
@raphql-modules/core
- Resolvers Composition — manages the app's resolvers wrapping
- Context building — each module can inject custom properties to the schema, and other modules can use it (for example, auth module can inject the current user, and other modules can use it)
- Dependency injection and module dependencies management — when you start, there is no need of using DI is your server. but when your server gets big enough with a large number of modules which depends on each other, only then, DI becomes a very help thing that actually simplifies your code a lot. USE ONLY WHEN NECESSARY ;)
You can find more tooling at your disposal like:
@raphql-modules/sonar — a small util that helps you find GraphQL schema and resolvers files, and include them.
@raphql-modules/logger — a small logger, based on winston 3, which you can easily use in your app.
Get Started
First thing, don't go full in! Start by simply moving your code into feature based folders and structures with your existing tools.
Then head over to https://graphql-modules.com/ and check out our tools and use them only when you see that they solve a real problem for you! (for us it has)
Also check out the repo's README and a number of example apps.
You probably have many questions — How does this compare to other tools, how to use those libraries with X and so on.
We will publish a series of blog posts in the coming weeks that will dive deep into each of the design decisions made here, so we want to hear your thoughts and questions, please comment here or on the Github repository!
Going to GraphQL Summit? I will be there and would love to get your questions and feedback on behalf of our team.
All those tools were built by a passionate group of individual open source developers, otherwise known as The Guild.
Below there is a section of more deep dive thoughts that we will publish separate posts about in the coming weeks:
Core Concepts and Deep Dive
Modularizing a Schema
Everyone is talking about schema stitching and GraphQL Bindings. Where does that fit into the picture?
Schema stitching is an amazing ability and concept, which helps you merge separated GraphQL servers into a single endpoint and opens up a lot of exciting use cases.
But, with all the excitement, we've missed something much more basic than that — sometimes we still want to work on a single logical server, but we just want to separate the code according to features.
We want to be able to do most of the merging work at build time, and only if really necessary, do the rest of the merging at runtime as a last resort.
We want to split the code into separate teams and even create reusable modules which define their external APIs by a GraphQL Schema.
Those modules can be npm modules, microservices or just separate folders inside a single server.
Separating your schema to smaller parts is easier when you are dealing with typeDefs and
resolvers— it's more readable and easy to understand.
We also wanted to allow developers to extend only specific types, without creating the entire
schema. With GraphQL schema, you have to specify at least one field under Query type, which is
something that we did not want to enforce on our users.
We see our approach as complementary to Schema Stitching and works together with it.
Feature-Based Implementation
One of the most important things in GraphQL Module's approach is the feature-based implementation.
Nowadays, most frameworks are separating the layers based on the role of the layer — such as controllers, data-access and so on.
GraphQL Modules has a different approach — separate to modules based on your server's features, and allow it to manage its own layers within each module implementation.
It's easier to think about apps in a modular way, for example:
Your awesome app needs a basic authentication, users management, user profiles, user galleries and a chat.
Each one of these could be a module, and implement its own GraphQL schema and its own logic, and it could depend on other modules to provide some of the logic.
Here's a simple example for a GraphQL Schema as we described:
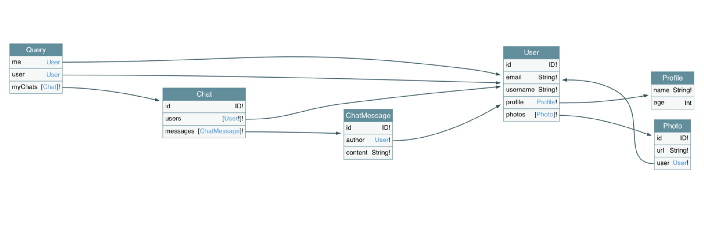
But if we think of apps in terms of features and then separate the schema by module, the modules separation will look like so:
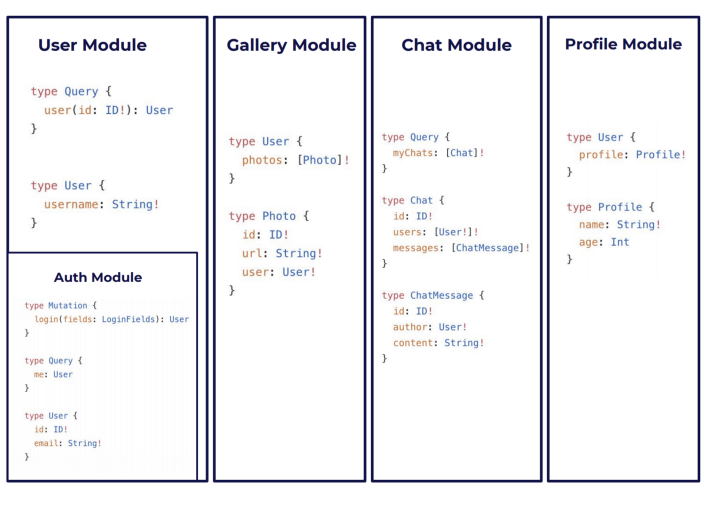
This way, each module can declare only the part of the schema that it contributes, and the complete
schema is a representation of all merged type definitions. Module can also depend, import and extend
and customize the contents on other modules (for example, User module, comes with Auth inside
it)
The result of course, will be the same, because we are merging the schema into a single one, but the codebase will be much more organized and each module will have its own logic.
Reusability of Backend Modules
So now that we understood the power of feature-based implementation, it's easier to grasp the idea behind code reusability.
If we could implement the schema and the core of Auth and User module as “plug-and-play” — we will be able later to import it in other projects, with very minor changes (using configuration, dependency injection, or module composition).
How could we reuse complete modules that hold part of a schema?
For example, let's take a User type.
Most of User type schemas will contain id, email and username fields. The Mutation type will
have login and the Query will have user field to query for a specific user.
We can re-use this type declaration.
The actual implementation might differ between apps, according to the authentication provider, database and so on, but we can still implement the business logic in a simple resolver, and use dependency injector and ask the app that's using the module to provide the actual authentication function (of course, with a complete TypeScript interface so we'll know that we need to provide it ;) ).
Let's take it one step further. If we would like to add a profile picture to a user, we can add a
new module named UserProfile and re-declare the User and Mutation types again:
type User {
profilePicture: String
}
type Mutation {
uploadProfilePicture(}This way, GraphQL Modules will merge the fields from this User type into the complete User type,
and this module will only extend the User type and Mutation type with the required actions.
So let's say that we have the schema — how can we make this module generic and re-use it?
This is how you declare this module:
import gql from 'graphql-tag'
import { GraphQLModule } from '@graphql-modules/core'
import { UserModule } from '../user'
import { Users } from '../user/users.provider'
export interface IUserProfileModuleConfig {
profilePictureFields?: string
uploadProfilePicture: (stream: Readable) => Promise<string>
}
export const UserProfileModule = new GraphQLModule<IUserProfileModuleConfig>({
imports: [UserModule],
typeDefs: gql`
type User {
profilePicture: String
}
type Mutation {
uploadProfilePicture( }
`,
resolvers: config => ({
User: {
profilePicture: (user: User, args: never, context: ModuleContext) => {
const fieldName = config.profilePictureField || 'profilePic'
return user[fieldName] || null
}
},
Mutation: {
uploadProfilePicture: async (
root: never,
{ image }: { { injector, currentUser }: ModuleContext
) => {
// using https://apollographql.com/docs/guides/file-uploads.html
const { stream } = await image
// Get the external method for uploading files, this is provided by the app as config
const imageUrl = config.uploadProfilePicture(stream)
// Get the field name
const fieldName = config.profilePictureField || 'profilePic'
// Ask the injector for "Users" token, we are assuming that `user` module exposes it for us,
// then, update the user with the uploaded url.
injector.get(Users).updateUser(currentUser, { [fieldName]: imageUrl })
// Return the current user, we can assume that `currentUser` will be in the context because
// of resolvers composition - we will explain it later.
return currentUser
}
}
})
})We declare a config object, and the app will provide it for us, so we can later replace it with a different logic for uploading.
Scaling the Codebase
Now that we broke our app into individual modules, once our codebase grows, we can scale each module individually.
What do I mean by scaling a codebase?
Let's say we start to have code parts we want to share between different modules.
The current way of doing it in the existing GraphQL world is through a GraphQL context.
This approach has proven itself to work, but at some point it becomes a big hassle to maintain, because GraphQL context is an object, which any part of the app can modify, edit and extend, and it can become really big pretty quickly.
GraphQL modules let each module extend and inject fields to the `context` object, but this is something that you should use with caution, because I recommend the `context` to contain the actual `context` — which contains data such as global configuration, environment, the current user and so on.
GraphQL modules only adds one field under the context, called injector which is the bridge that
lets you access your GraphQLApp and the application Injector, and it lets you fetch your module's
config and providers.
Modules can be a simple directory in a project or in a monorepo, or it could be a published NPM module — you have the power to choose how to manage your codebase according to your needs and preferences.
Dependency Injection
GraphQL Modules' dependency injection is inspired by .NET and Java's dependency injection which has proven itself to work pretty well over the years. With that being said, there were some issues with .NET and Java's APIs, which we've tried to list and go through. We ran into some pretty interesting conclusions.
We've learn that it's not something that should be forced. Dependency injection makes sense in some specific use cases and you should need to use it only when it's necessary and when it helps you move faster. So this concept should come more and more in handy as we scale up, we can simplify things, maintain our code with ease and manage our teams' contributions!
Having GraphQL Modules deployed across all of our Enterprise customers while also being used on our smaller applications, lead us to believe that we've found the optimal point of where you should use the concept of dependency injection, and when not.
We've also came with the optimal API for dependency injection. It's extremely easy to understand, and use.
After a long research of the existing dependency injection solutions for JavaScript, we've decided to implement a simple Injector, that supports the needs of GraphQL-Modules ecosystem, and support circular dependencies and more.
We've simplified the Dependency Injection API and exposed to you only the important parts, that we believe that are necessary for a GraphQL server development.
Authentication
Check out the related blog post we wrote about it: /blog/graphql-modules-auth
Testing and Mocking
On our Enterprise applications, when we started using dependency injection, we no longer had to manage instances and bridge them together.
We gained an abstraction that allowed us to test things easier and mock all http requests.
Yes, mocking. DI really shines here.
Thanks to mocking we can simulate many scenarios and check the backend against them.
And when your codebase grows, you need to start thinking about managing dependencies between modules and how to avoid things like circular dependencies — unless you use DI which solves that problem for you.
With the power of dependency injection, you can easily create a loose connection between modules, and base this connection on a token and on a TypeScript interface.
It also means that testing is much easier — you can take your class/function and test it as an independent unit, and mock its dependencies easily.
Summary
We see GraphQL Modules as the framework that finally being built from the ground up on the new and exciting capabilities of GraphQL and Apollo, while combining it in the right way with good old software best practices for scale like modularizations, strong typings and dependency injection.
Now go and try it out at graphql-modules.com
All Posts about GraphQL Modules
- GraphQL Modules — Feature based GraphQL Modules at scale
- Why is True Modular Encapsulation So Important in Large-Scale GraphQL Projects?
- Why did we implement our own Dependency Injection library for GraphQL-Modules?
- Scoped Providers in GraphQL-Modules Dependency Injection
- Writing a GraphQL TypeScript project w/ GraphQL-Modules and GraphQL-Code-Generator
- Authentication and Authorization in GraphQL (and how GraphQL-Modules can help)
- Authentication with AccountsJS & GraphQL Modules
- Manage Circular Imports Hell with GraphQL-Modules