
This blog is a part of a series on GraphQL where we will dive deep into GraphQL and its ecosystem one piece at a time
- Part 1: Diving Deep
- Part 2: The Usecase & Architecture
- Part 3: The Stack #1
- Part 4: The Stack #2
- Part 5: The Stack #3
- Part 6: The Workflow
Now that we have discussed GraphQL, and also about some architectural considerations when starting off, let's look at the next important step in the puzzle — choosing the right tech stack for your use case and building the development workflow which suits you best in this blog.
Technology changes and evolves constantly as we have already seen it happening all these days. So, rather than worrying too much about the technology you choose, it is better to choose a tool, library or platform which allows for incremental changes without lock-in. Using the list in the previous blog post might actually help in your decision-making process.
But, today I am going to assume a tech stack (the GraphQL Tech Stack that I work with every day to build Timecampus) and walk you through. The reason I say "GraphQL" Tech Stack is because, this is just a part of the complete stack I use and there is more to it which we will discuss sometime down the line in a different blog.
NOTE: While these work great for me, this is an area of continuous exploration for me, and I don't mind replacing X with Y as long as the effort is really worth it from a future perspective (we will explore more on what they are and why we use these as we go along). With that, let's start.
There is no doubt that VSCode has become the defacto editor which developers user these days. And it definitely deserves the recognition and credit it gets. VSCode comes with amazing extensions and tooling for GraphQL and its ecosystem built by the community and if you work with GraphQL and Typescript, I would say it is pretty much a standard editor which you would definitely want to use.
For instance, just do a search for “GraphQL” in the marketplace, and this is what you get:
and the ecosystem is growing even more every day and this makes VSCode indispensable for our stack.
GraphQL Config acts as a single configuration point for all that we do with GraphQL. This is important because when working on projects, it is important to have little to no repetition (DRY principle) and having a separate config file for every tool will start getting overwhelming and messy over time since we will have multiple places to maintain.
We can specify all that we want regarding GraphQL in a single .graphqlrc file as mentioned in the
docs starting from the location to the schema, the GraphQL documents (queries and mutations), and
also the configuration for extensions which we use with it.
Not just this, a single .graphqlrc file can be used to specify all the configuration you need for
multiple projects that you use in your workspace.
For eg. it can integrate with our VSCode GraphQL extension to provide autocompletion, intellisense and so on, provide all the config needed to do code generation with GraphQL codegen, linting with GraphQL ESLint and can also pave way to all the other tools we may integrate in the future.
A .graphqlrc.yml file may look something like this:
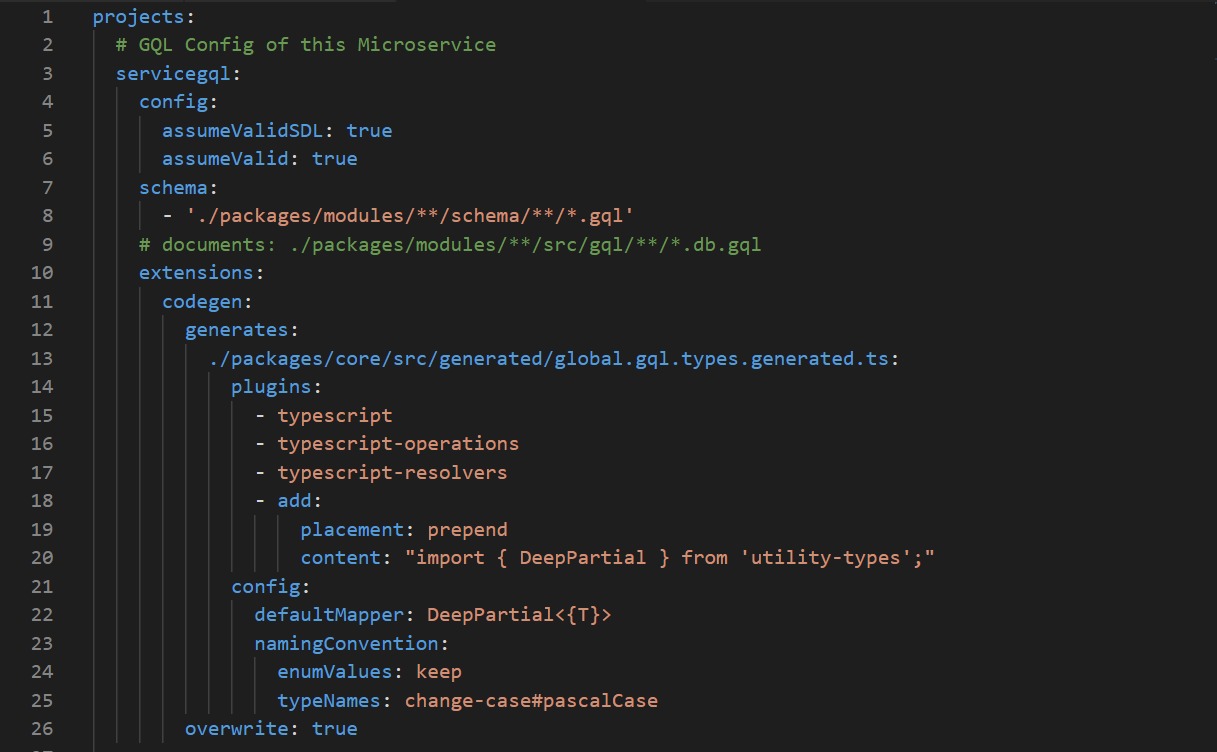
GraphQL Config Snippet
The next thing which comes to mind is a VSCode extension which can provide the support for all the things you need to do with GraphQL. Originally developed by the amazing people at Prisma this extension was later donated to the GraphQL Foundation and the reason this extension is really promising is because, it provides everything you need to work with GraphQL including syntax highlighting, autocompletion, validation, SDL navigation, execute, operations, support for tagged template literals and all of this with support for GraphQL Config and it works great.
NOTE: If you are using the Apollo Stack (like
Federation), I would recommend you to go with
Apollo VSCode instead since it
provides support for things like apollo.config.js (which integrates with the schema registry),
federation directives and so on.
The next thing which is important when you work with GraphQL as a team is following a set of standards so that everyone is on the same page. This is where using a linter like GraphQL ESLint would really help. The beauty is that it integrates seamlessly with GraphQL Config, supports ESLint natively and also provides some inbuilt rules which is a great start to work with like consistent case, making naming of operations mandatory, forcing a deprecation reason and so on which can be of great use as you scale up with GraphQL.
A sample .eslintrc file to be used for GraphQL ESLint would look something like this:
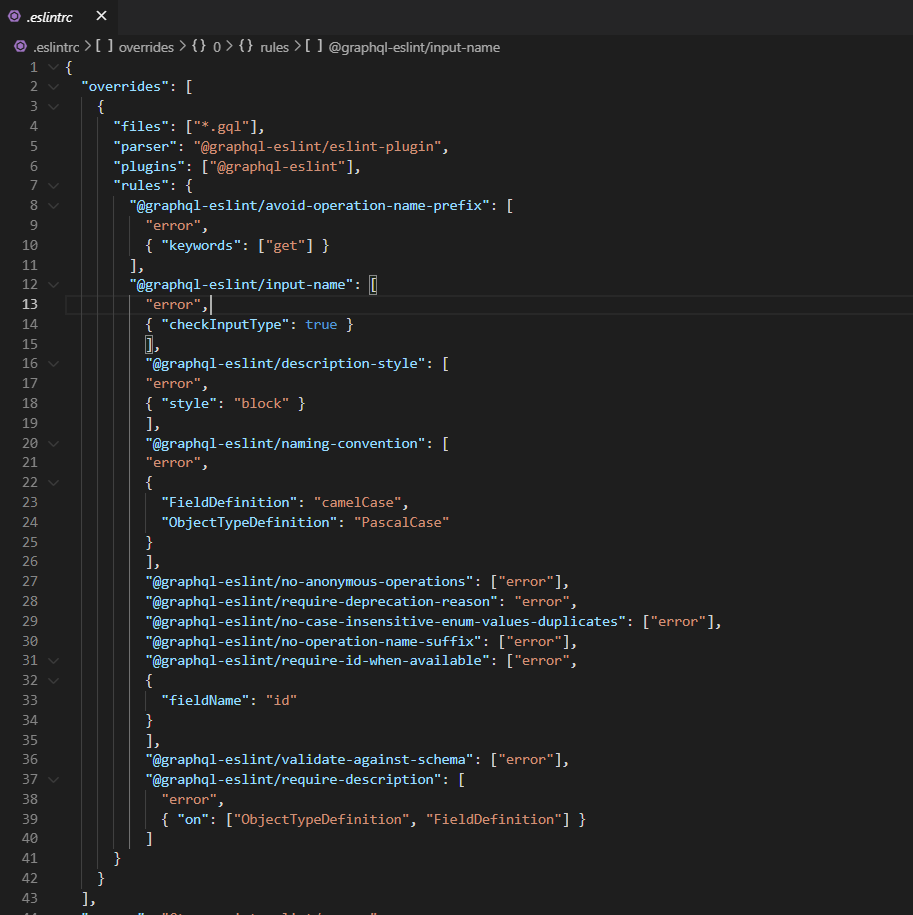
GraphQL ESLint snippet
How do you make collaborating with GraphQL very easy? And how do you do this in such a way that you have all the information you need to take a specific action? What if there are breaking changes to your schema? Errors and issues may creep in anywhere and at anytime.
This is where GraphQL inspector comes in. It provides a platform with various functionalities like schema validation, coverage, finding similar operations, inspecting the difference between different versions of the schema, mock your schema with test data and also a Github application to do all this for you when you raise a pull request.
For eg. this is how finding the coverage of your operations against the schema looks like:
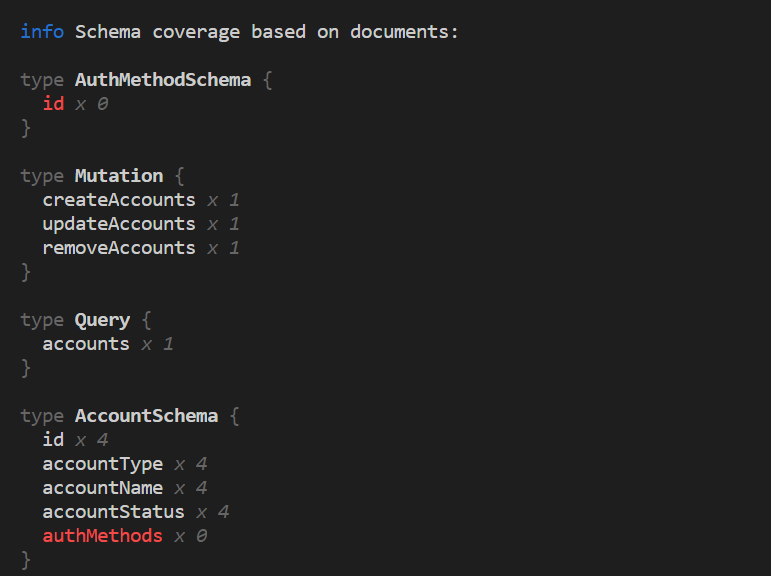
GraphQL Coverage
And if you want to find similar fields/types within your schema, this is how it will look like:
GraphQL Similarity
When I initially started off with Typescript few years ago, I was not sure of the advantages it would provide me over time for the effort I am putting in to make the code I write completely typed. To be honest, it takes a lot of effort and sometimes can be painful. But, this perception changed over time especially when I started working with GraphQL and TypeScript.
The reason GraphQL works great with TypeScript is mainly because of a lot of similarities between them with both being strongly typed, providing a clear path to documentation, offering great validations and also a great ecosystem built both on top of TypeScript and GraphQL.
This will become more evident as we go through this blog. But, writing the types manually for each and every field in the schema or for every operation and keeping them updated can be a huge task. This is where a lot of amazing tools come in like GraphQL Codegen, Typed Document Node, TypeGraphQL and so on.
And on top of this, the beauty is that, with GraphQL and Typescript, we can actually make the
end-end stack fully typed (which is what we do at Timecampus). And
after seeing all this happening, even graphql-js is on its
path to migration with Typescript.
There are a lot of GraphQL servers out there. And we even spoke about some of those in our
first blog post. While it is not necessary to pick an
out-of-the-box GraphQL server since you can build your own using graphql-js , it may not be a
smart choice since you might not want to reinvent the wheel.
This is where I use GraphQL Helix which provides me a GraphQL server and also the option to selectively replace any module that I need to work for your use case. This is very evident from the examples' folder of the repository demonstrating various use-cases like subscriptions, csp, graphql-modules, persisted-queries and so on and also with various frameworks like express, fastify, koa.
And since there are no outside dependencies except for graphql-js there is also no bloat to the
same unlike other graphql servers. If you want to see how other GraphQL servers perform, you might
want to have a look at this.
We did discuss how Typescript and GraphQL works seamlessly well with each other. But what if we can generate all that we can from our SDL which provides majority of the information that one needs including name of the schema, fields, types, and so on.
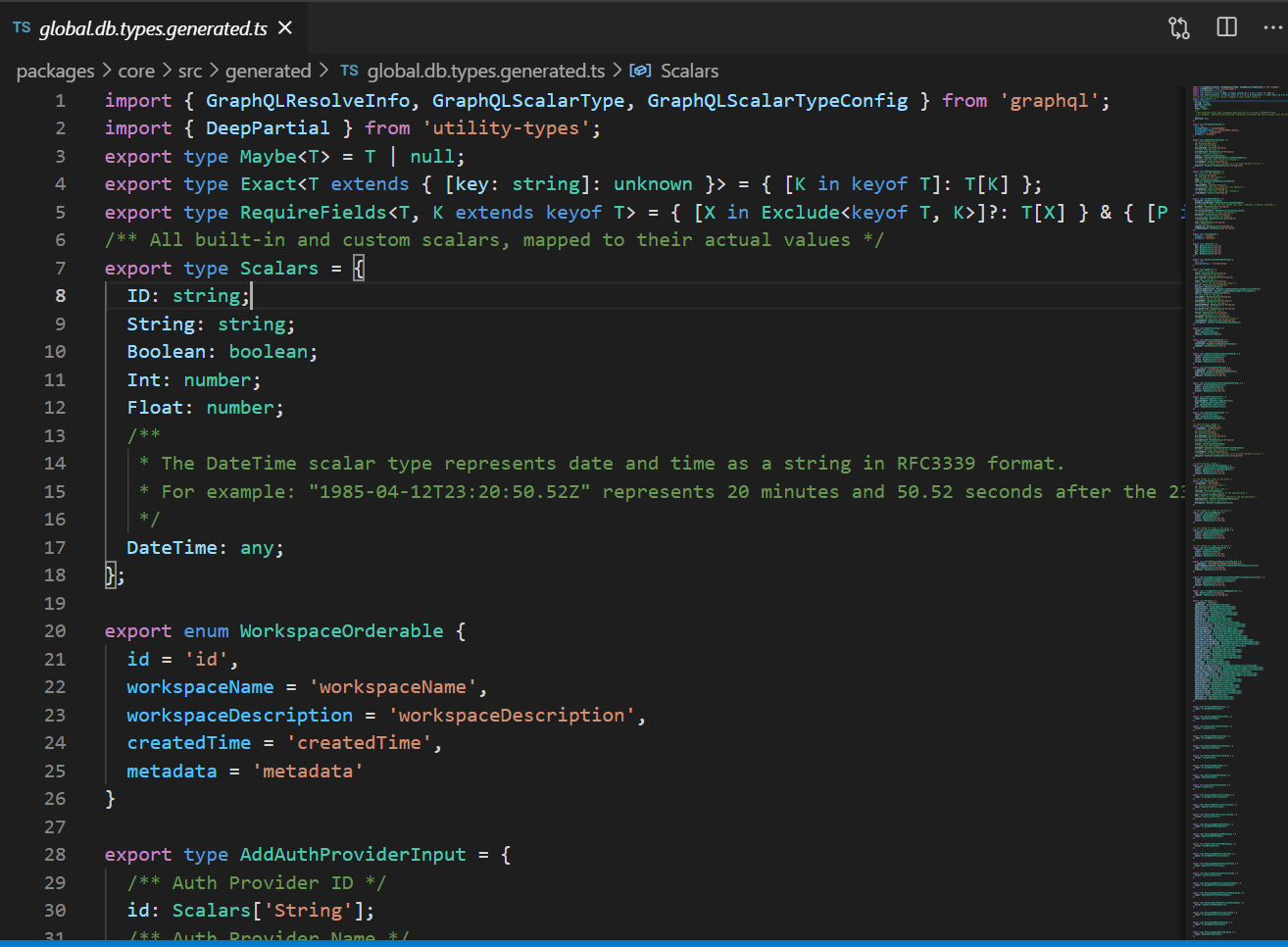
And this is where GraphQL Codegen plays a major role. You can generate all the types, interfaces and so on, and it also comes with a lot of plugins and presets to help you work with not just Typescript, but also other languages and tooling. All we have to do is import the type we need and just use it making it really simple. And every time we change the schema, we can just regenerate the types. Also, it integrates seamlessly with GraphQL Config making it really easy to maintain.
For eg. this is how the generated types look like:
There are more tools, libraries and platforms we have to talk about as part of our GraphQL Stack, and we will be continuing our discussion in the next blog post. Hope this was insightful.
If you have any questions or are looking for help, feel free to reach out to me @techahoy anytime.
And if this helped, do share this across with your friends, do hang around and follow us for more like this every week. See you all soon.